مجله خبری برنامهنویسی پایتون
مرکز آموزش و رقابت برنامه نویسی پایتون

زبان پایتون (Python) در سال ۱۹۹۱ توسط یک برنامهنویس هلندی به نام گیدو ون روسوم (Guido van Rossum) ابداع شد و از آن زمان تا کنون رشد قابل ملاحظهای را شاهد بوده است.
اگر چه وی در آن زمان گفته بود: «من به هیچ وجه قصد ندارم زبانی بسازم که به طور گسترده مورد استفاده قرار بگیرد» ولی اکنون و با گذشت نزدیک به سه دهه از آن تاریخ، پایتون تقریباً تمام رقبای خود را کنار زده و به اندازهای محبوبیت یافته که حتی افراد مبتدی نیز کدنویسی را با آن شروع میکنند.
در یک سال گذشته، «Python» یکی از کلماتی بود که شهروندان آمریکایی بسیار زیاد در گوگل جستجو کردهاند، حتی بیشتر از نام ستارههای تلویزیونی.
طبقه بندی موضوعی
-
برنامه نویسی
(۳۳) -
اخبار
(۲۱) -
جشنواره تخفیف
(۶) -
استخدام
(۴) -
یادگیری ماشین با پایتون
(۳) -
مطالب آموزشی
(۵) -
متن کاوی
(۲۰) -
چالش
(۱) -
کتاب
(۱) -
کتابچه
(۳) -
وبینار
(۱)
کلمات کلیدی
آموزش پایتون
متن کاوی با پایتون
python
متن کاوی
یادگیری ماشین
پایتون
text mining
استخدام برنامه نویس پایتون
یادگیری ماشین با پایتون
پایتون در یادگیری عمیق
Pandas
پایتون برای علم داده
استخدام
محبوب ترین زبان برنامه نویسی
هوش مصنوعی
عبارت منظم در پایتون
replace
استخراج متن در پایتون
کد تخفیف یلدا
یادگیری عمیق
وب سایت آموزشی پایتون
NumPy
Matplotlib
Cheat Sheet
جشنواره تخفیف
پردازش تصویر
ریاضی
jupyter notebook
وبینار
ات ساین
بایگانی
- فروردين ۱۳۹۹ (۲)
- اسفند ۱۳۹۸ (۳)
- بهمن ۱۳۹۸ (۱)
- دی ۱۳۹۸ (۳)
- آذر ۱۳۹۸ (۸)
- شهریور ۱۳۹۸ (۳)
- تیر ۱۳۹۸ (۲)
- خرداد ۱۳۹۸ (۱)
- ارديبهشت ۱۳۹۸ (۳)
- فروردين ۱۳۹۸ (۷)
- اسفند ۱۳۹۷ (۴)
- بهمن ۱۳۹۷ (۱)
- دی ۱۳۹۷ (۱)
- آذر ۱۳۹۷ (۴)
- آبان ۱۳۹۷ (۱۸)
- مهر ۱۳۹۷ (۱۴)
آخرین مطالب
-
۹۹/۰۱/۱۱تخفیف بزرگ چالش پایتون در سال 99
-
۹۸/۱۰/۱۲کتابچه پایتون : کتابخانه scrappy
-
۹۸/۱۰/۱۰کتابچه پایتون : کتابخانه PIL
پیوندها

شبکه اجتماعی لینکدین اطلاعاتی را در مورد مشاغلی که طی چند سال اخیر بیشترین رشد را تجربه کردهاند منتشر کرد و بر اساس آن مشخص شد مهارتهای مرتبط با حوزه فناوری و داده از جمله بخشهایی بودند که میزان اشتغالزایی در آنها سریعترین رشد را داشته است و به خصوص آن دسته از افرادی که در عرصه مرتبط با دادهها فعالیت میکنند بیشتر از بقیه این رشد را پیش روی خود دیدهاند.
در رتبه نخست لیست مشاغل با بیشترین رشد، مهندسان حوزه یادگیری ماشینی قرار دارند که گفته میشود این عنوان شغلی بین سالهای ۲۰۱۲ تا ۲۰۱۷ میلادی رشد ۱۰ برابری را تجربه کرده است. پس از آن متخصصان حوزه داده پررونق ترین بازار کاری را پیش روی خود دیدند که در این بازهی زمانی این حوزه رشد ۷ برابری داشت. همچنین گفته شد کارشناسان توسعهدهندهی کلان داده و مهندسان پشتیبانی هم رشد ۶ برابری داشتند.
به گزارش وبسایت Zdnet؛ در گزارش نهایی لینکدین آمده است: «مجموعه جامعی از مهارتهایی که رشتههای مختلف را پوشش میدهند در سال های اخیر بیشترین تقاضا را داشتهاند. بیشتر این فرصتهای شغلی در لیست جاری رشتههای مختلفی را شامل میشدند که قابلیت استفاده از آنها در صنایع مختلف وجود داشت.»
۱۰ عنوان شغلی برتر با پررونقترین بازارکاری در پنج سال گذشته بر اساس گزارش لینکدین عبارتند از:
- مهندس یادگیری ماشینی (رشد ۹.۸ برابری تعداد کارفرمایان نسبت به سال ۲۰۱۲)
- کارشناس داده (رشد ۶.۵ برابری نسبت به سال ۲۰۱۲)
- توسعه دهنده سیستمهای فروش (رشد ۵.۷ برابری نسبت به سال ۲۰۱۲)
- مدیر ارتباط با مشتری (رشد ۵.۶ برابری نسبت به سال ۲۰۱۲)
- توسعهدهنده کلان داده (رشد ۵.۵ برابری نسبت به سال ۲۰۱۲)
- مهندس پشتیبان (رشد ۵.۵ برابری نسبت به سال ۲۰۱۲)
- توسعهدهنده نرمافزارهای کاربردی (رشد ۵.۱ برابری نسبت به سال ۲۰۱۲)
- مدیر علوم داده (رشد ۴.۹ برابری نسبت به سال ۲۰۱۲)
- شرکای تجاری برندها (رشد ۴.۵ برابری نسبت به سال ۲۰۱۲)
- توسعهدهنده سیستمهای پشتیبانی (رشد ۴.۵ برابری نسبت به سال ۲۰۱۲)
در این دوره تمامی مراحل لازم برای ساختن یک ماشین یادگیری تشخیص ایمیل اسپم آموزش داده میشود. آموزشها از مباحث تئوری احتمالات آغاز شده و تا یادگیری Bayesian ادامه مییابد. سپس مراحل لازم جهت پیادهسازی مباحث تئوری در پایتون از 0 تا 100 طی شده است.
مخاطبان این دوره میتوانند روش یادگیری Bayesian را که یکی از مشهورترین شیوههای یادگیری ماشین (Machine Learning) میباشد، بصورت تئوری فراگرفته و با بکار گیری آن در عمل به درک و شهود واقعی از آن برسند.
مقدمات برنامهنویسی این دوره نیز بصورت کامل در آن آموزش داده میشود تا حتی عزیزانی که در حد مقدماتی و پایینتر با پایتون آَشنایی دارند، بتوانند با ما همراه باشند.
پروژه عملی آموزش داده شده در این دوره میتواند در کاربردهای وسیعتر پردازش متن، از جمله تشخیص انواع متون از یکدیگر (مثل تشخیص متون سیاسی از غیر سیاسی، ورزشی از غیر ورزشی و ...) بکار گرفته شود. این دوره برای کسانی که پیش زمینه اندکی از ماشین لرنینگ و یا آمار و احتمالات در حد مقدماتی دارند مناسب میباشد.
لازم به ذکر است جهت درک بهتر، در این دوره از هیچ کتابخانه آماده هوش مصنوعی و ماشین لرنینگ و دیپ لرنینگ استفاده نشده و تمامی مراحل لازم از 0 تا 100 پیادهسازی شده است.
📘 فرمت تمام ویدئوها بصورت mp4 می باشد که به راحتی با نرم افزارهای پخش مدیا اجرا خواهند شد.
📘 در صورت بروز هر گونه مشکل در خرید و دانلود با پست الکترونیکی sendticket.py@gmail.com با ما در ارتباط باشید.
📘 سرفصل دوره در بخش زیر قابل مشاهده میباشد، بخشهای که به رنگ آبی است بصورت رایگان قابل دانلود میباشد.
قیمت: ۵۰,۰۰۰ تومان
مترجم : آزاده رضازاده همدانی
ویدئوهای آموزش یادگیری ماشین یا پایتون [کلیک کنید]
در دنباله آموزشهای یادگیری ماشین, مثال رگرسیون بر روی دادههای ارزش سهام را ادامه میدهیم: کدهایی که در مرحله قبل نوشتیم به صورت زیر است:
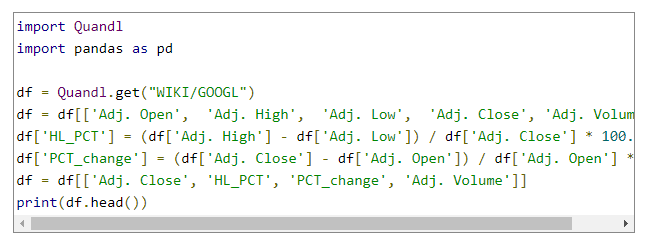
در ادامه باید تعدادی از کتابخانهها را import کنیم:

· numpy: داده ها را به آرایه ( numpy Array ) تبدیل کرده تا بتوان آنها را در اختیار scikit-learn قرار داد.
· ماژول پیش پردازش Preprocessing و اعتبارسنجی CrossValidation: که بیشتر در طول کدنویسی در مورد آنها توضیح خواهیم داد. اما به طور خلاصه کافی است بدانید که پیش پردازش, مرحله پاکسازی و مقیاس بندی دادهها قبل از شروع عملیات یادگیری ماشین و اعتبار سنجی فاز آزمایش نتایج حاصل از اجرای الگوریتم یادگیری ماشین است.
· الگوریتم linear Regression : همان الگوریتم رگرسیون خطی است.
· Svm: الگوریتم یادگیری ماشین به کار رفته برای نمایش نتایج
تا این مرحله دادههای سودمند را دریافت کردهایم اما واقعا یادگیری ماشین چگونه کار میکند؟ در یادگیری بانظارت, مجموعهای از ویژگیها Features و برچسبها Labels را داریم. ویژگیها, خصوصیات توصیفی هر نمونه و برچسب, کلاسی است که در واقع نمونه به آن تعلق دارد و قرار است توسط یادگیری ماشین, پیشبینی شود. یکی از مثالهای رایج در رگرسیون, پیش بینی ارزش حق بیمه اشخاص است. شرکت بیمه اطلاعاتی از جمله سن, سوابق تخلفات رانندگی, سوابق سوء پیشینه و میزان اعتبار بانکی شخص را جمع آوری میکند. البته این دادهها را از طریق اطلاعات مشتریان گذشته دریافت کرده تا حق بیمه مطلوب را پیش بینی نماید. در این مثال مشخصات هر مشتری به عنوان ویژگیها و حق بیمه به عنوان برچسب مرتبط با هر مشتری در نطر گرفته میشود.
در مورد مثال بالا ویژگیها و برچسب چگونه تعیین میشود؟ از آنجایی که هدف پیش بینی قیمت است آیا قیمت به عنوان برچسب در نطر گرفته میشود؟ ویژگیها چطور؟ ویژگیها عبارتند از : قیمت فعلی, درصد high-low و درصد نوسانات تغییرات. قیمت آینده Future price به عنوان برچسب در این مثال در نظر گرفته میشود.
حال کمی جلوتر برویم و خطوطی جدید را اضافه نماییم:

در اینجا ابتدا ستونی را به عنوان ستون پیش بینی(forecast_col) تعیین میکنیم. سپس کلیه مقادیر نامعتبر NAN(not a number) را با مقدار99999- جایگزین مینماییم. از آنجایی که نمیتوان یک داده ناقص با مقادیر نامعتبر را به دستهبند یادگیری ماشین ارسال کرد لذا راهکارهای متعددی برای حذف دادههای ناقص وجود دارد. از جمله: جایگزینی مقادیر نامعتبر با مقدار 99999- که داده را به منزله یک داده پرت تلقی میکند. و همچنین حذف کلیه دادههای ناقص. اما این کار احتمال از دست دادن حجم عطیمی از اطلاعات مفید را ایجاد میکند.
بر خلاف مجموعه داده مربوط به ارزش و تعداد سهام که شامل دادههای کامل و بدون نقصی میباشد, مجموعه دادههای دنیای واقعی بسیار ناقص و نامعتبر و یا به اصطلاح کثیف Messy میباشند. اما شما لزوما نیازی به تضمین صحت همه دادهها نخواهید داشت و حتی میتوانید شرط ببندید که دادههای واقعی مورد استفاده در الگوریتم یادگیری ماشین حتما دارای نقصهایی میباشند. بنابراین باید مراحل آموزش و آزمایش نتایج را به ظور زنده بر روی دادههای واقعی یکسان با تمام ویژگیهای آنها انجام داد.
در نهایت تعداد مواردی که میخواهیم پیشبینی کنیم تعیین میشود (forecast_out) .در بسیاری موارد به طور مثال پیش بینی حق بیمه, "در همان لحظه", تنها به یک عدد نیاز داریم درحالی که اصولا بدنبال پیشبینی تعداد مشخصی از دادهها هستیم. معمولا هدف, پیش بینی %1 تعداد کل رکوردهای موجود در دیتاست در آینده است. این بدین معنی است که مثلا با داشتن 100 روز ارزش سهام ,هدف, پیش بینی ارزش سهام در یک روز آینده است. پس آنچه ا که میخواهید, مشخص کنید! اگر تمایل به پیش بینی قیمت فردا را دارید مقدار forecast-out=1 خواهد بود. و اگر مقدار forecast-out=10 باشد یعنی شما قابلیت پیش بینی قیمتها تا ده روزآینده (یک هفته و نیم آینده) را خواهید داشت.
در مثال اولیه مجموعه ای از مقادیر فعلی را به عنوان ویژگی و قیمت آینده (منظور از آینده %1 تعداد دادههای موجود در دیتاست میباشد )را به عنوان برچسب در نظر گرفتیم. از آنجایی که همه ستونهای فعلی را به عنوان ویژگی در نظر گرفته ایم لذا با یک عملیات ساده موجود در کتابخانه pandas , ستونی جدید برای برچسب ایجاد می نماییم.
تا اینجا ویژگیها و برچسب همه نمونه ها معین گردید. در مرحله بعد پس از انجام عملیات پیش پردازش , نمونه ها در اختیار الگوریتم رگرسیون قرار خواهند گرفت که در بخش های آینده پیرامون آن صحبت خواهد شد.
مترجم : آزاده رضازاده همدانی
ویدئوهای آموزش یادگیری ماشین یا پایتون [کلیک کنید]
پیشنیاز : Scikit-learnو Pandas, matplotlib
(اگر نسخه علمی از پیش کامپایل شده پایتون مثل ACtivePython را ذز اختیار دارید پس نیازی به نصب کتابخانههای numpy,Scipy,Scikit-learn,Matplotlib,pandas نیست در غیر این صورت آنها را به صورت جداگانه نصب نمایید)
همچنین علاوه بر نصب کتابخانههای فوق , کتابخانه quandl را نیز نصب نمایید. (به qو یا Q هنگام import کتابخانه quandl توجه نمایید!!)
منظور از رگرسیون در یادگیری ماشین چیست؟ هدف در رگرسیون : دریافت دادههای پیوسته, پیداکردن متناسب ترین معادله برای دادهها , و سپس پیش بینی مقدار جدید برحسب معادله بدست آمده. به طور مثال در رگرسیون خطی تنها باید بهترین معادله خط را مطابق شکل زیر پیدا نمود:
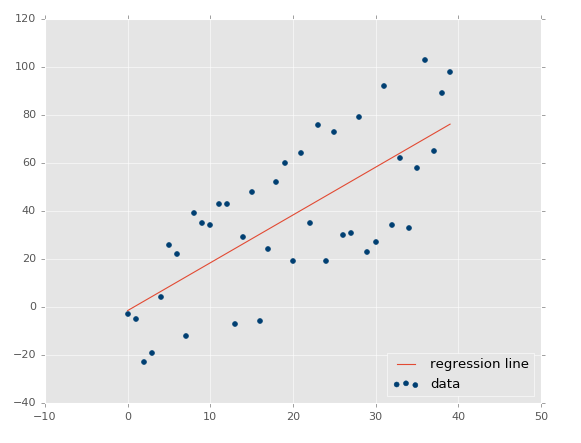
با داشتن معادله خط میتوان دادههای جدیدی که درآینده دریافت میشوند را تخمین و پیش بینی نمود. به طور مثال فرض کنید در شکل بالا محور افقی نشاندهنده زمان (تاریخ) و محور Y عمودی نشان دهنده قیمت باشد. بنابراین با داشتن معادله خط میتوان قیمتها را در اینده پیش بینی نمود.
یکی از کاربردهای مرسوم رگرسیون پیش بینی ارزش سهام است بدین صورت که بادرنظر گرفتن روندو جریان قیمت در طول زمان , و با داشتن مجموعه دادههای پیوسته, ارزش روند جدید سهام در آینده پیش بینی میشود.
رگرسیون نوعی یادگیری ماشین با ناظر است. در این حالت فرد خبره(محقق) بارها و بارها نمونهها و ویژگیها را در اختیار ماشین قرار داده سپس برچسب کلاس دسته بندی صحیح هریک, را نیز در اختیار آن قرار میدهد تا بدین ترتیب ماشین پروسه دستهبندی را فرابگیرد. پس از آن که ماشین آموزش داده شد, نوبت به مرحله آزمایش (تست) ماشین میرسد. بدین صورت که نمونههای دیده نشده ای که برچسب کلاس آن برای فرد خبره معلوم اما برای ماشین نامعلوم و نامشخص است در اختیار ماشین قرار داه میشود.پاسخهای حاصل از تشخیص ماشین با پاسخهای اصلی درست مقایسه شده و میزان صحت ماشین اندازهگیری میشود.اگر صحت به اندازه کافی بالا باشد محقق میتواند این الگوریتم را بر روی دادههای واقعی اعمال نماید.
از آنجایی که مثال پرکاربرد رگرسیون, پیش بینی ارزش سهام است پس میتوان با مثال زیر شروع کرد:
در ابتدا به داده احتیاج داریم. گاهی اوقات بدست آوردن این دادهها کار آسانی است اما گاهی باید اطلاعات مدنظر خود را از بین دادههای موجود بیرون کشید مشابه کاری که در این مثال انجام شده است:
در اینجا از اطلاعات ساده موجود پیرامون ارزش و تعداد سهام در کتابخانه Quandle استفاده خواهیم کرد که قبلا توسط google جمع آوری شده است.

در متن بالا Q در کلمهQuandle باید با حروف کوچک نوشته شود.
در حال حاضر این اطلاعات در اختیار ماست: همانطور که مشاهده میکنید حجم آنها برای شروع کمی زیاد است.
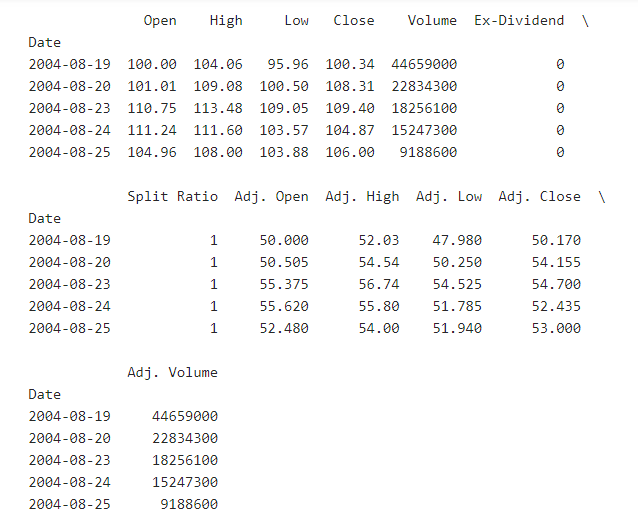
همانطور که قبلا در مقدمه هم توضیح داده شد, در یادگیری ماشین بخشی وجود دارد که هدف آن کاهش میزان دادههای ورودی است. در این مثال خاص چند ستون داریم که بسیاری ازآنها زاید و تکراری بوده و تنها یک زوج از آنها ثابت بوده و تغییر نمیکند. احتمالا همه با این موضوع موافقیم که داشتن همزمان داده های Regular و دادههای Adjusted امر مطلوبی نیست. ستونهای Adjasted مطلوبترین اطلاعات را در اختیار ما قرار میدهند در حالی که ستونهای regular حاوی اطلاعات روزانه بوده که شاید خیلی مفید نباشند. مثلا سهام دارای بخشی به نام stock splits(تقسیم سهام) میباشد که ممکن است یک سهم به 2 سهم تقسیم شود و ارزش سهام نصف شده در حالی که ارزش آن شرکت نصف نشود. ستونهای adjusted به مرور و در گذر زمان برای stock splits تنظیم میشوند از اینرو به منظور تحلیل دادهها بسیار قابل اعتمادتر هستند. حالا بهتر است کمی پیش برویم و نمونه کوچکی از داده ها را دقیق تر بررسی کنیم:

دراینجا فقط ستونهای adjusted و همچنین ستون volume (تعداد سهام )راداریم. لازم است پیرامون نکاتی مهم بحث شود:
· آیا این که افراد تصور میکنند که یادگیری ماشین قادر به خلق اطلاعات از هیچ است صحیح میباشد؟ خیر در واقع باید اطلاعاتی حتما موجود باشد تا یادگیری ماشین بتواند آن را برجسته و مشخص نماید.
· شما به داده های با معنی احتیاج دارید. حال چگونه متوجه خواهید شد که این دادهها با معنی هستند یا خیر؟ بهترین پاسخ برای این سوال این است که از فکر و مغز خود استفاده کنید و در مورد آن فکر کنید.
· آیا قیمتهای گدشته نشاندهنده قیمتهای آینده هستند؟ بعضی از افراد اینگونه فکر میکنند اما در گذر زمان ثابت شده است که این تصور اشتباه است.
· الگوهای گذشته چطور؟ آیا در پیشبینی آینده موثر هستند؟ این نظریه تا حدودی میتواند خوب باشد اما در کل هنوز ضعیف است.
· در راستای بررسی الگوهای گدشته, آیا بررسی روابط بین تغییرات ارزش سهام و تعداد سهام (volume) در طول زمان به پیشبینی ارزش سهام در آینده کمک خواهد کرد؟بله این دیدگاه تا حدودی نسبت به نظرات قبلی بهتر شده است.
پس همانطور که میبینید داشتن داده بیشتر به منزله بهتر بودن داده نیست و هدف در یادگیری ماشین کسب مفیدترین دادهها میباشد. بدین منظور گاهی نیازاست تاتغییراتی بر روی اطلاعات خام اولیه صورت پذیرد.
میزان
نوسانات روزانه مثلا کمترین تغییرات رادر نطر بگیرید. به نظر شما بهتر است داده ها
به سادگی مطرح شده (Open, High, Low, Close)و یا به صورت نوسانات و درصد تغییرات( Close, Spread/Volatility,
%change )؟ تصور من این
است درصد تغییرات اطلاعات مفیدتری را به ما میدهد.
بنابراین همانگونه که تاکنون مشاهده کردید همه دادههای موجود اطلاعات مفیذی را در اختیار شما قرار نمیدهند, بلکه باید قبل از در اختیار گذاشتن داده ها به صورت ورودی الگوریتم یادگیری ماشین, تغییراتی را بر روی آنها انجام دهید.
در این بخش مقدار (high-low)/low*100 محاسبه میشودکه نشاندهنده درصد انتشار بر اساس ارزش close بوده و میزان نوسانات را اندازهگیری میکند:

در انتها درصد تغییرات روزانه محاسبه میشود:

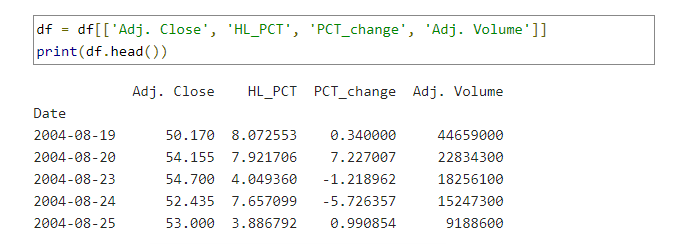
و چهار ستون زیر نمایش داده میشود:
به عنوان یکی از شاخههای وسیع و پرکاربرد هوش مصنوعی، یادگیری ماشین (Machine learning) به تنظیم و اکتشاف شیوهها و الگوریتمهایی میپردازد که بر اساس آنها رایانهها و سامانهها توانایی تعلٌم و یادگیری پیدا میکنند
هدف یادگیری ماشین این است که کامپیوتر (در کلیترین مفهوم آن) بتواند به تدریج و با افزایش دادهها کارایی بهتری در انجام وظیفه مورد نظر پیدا کند. گستره این وظیفه میتواند از تشخیص خودکار چهره با دیدن چند نمونه از چهره مورد نظر تا فراگیری شیوه گامبرداری روباتهای دوپا با دریافت سیگنال پاداش و تنبیه باشد.
پیش بینی می شود در آینده استفاده از زبان برنامه نویسی پایتون، گسترش بسیار بیشتری داشته باشد
در حوزه تحلیل داده، یادگیری ماشین و علم داده نیز، استفاده از پایتون بسیار قابل توجه است به طوری که این زبان پرکاربردترین زبان در حوزه علم داده و یادگیری ماشین می باشد:
با توجه به درخواستهای مخاطبین جهت برگزاری کلاسهای پرسش و پاسخ با مدرس دوره، تصمیم گرفته شد تا دوره یادگیری ماشین با پایتون به صورت هفتگی برگزار شود.
در این دوره، که از اول آذر 97 شروع خواهد شد هر هفته دو ویدئو از طریق سامانه کلاس کوئرا و کانال یادگیری ماشین برای مخاطبین ارسال خواهد شد.و تمرینات و تکالیفی در این سامانه توسط مدرس تعیین و تصحیح خواهد شد. مخاطبینی که تمایل دارند خود را درگیر این دوره نمایند و چالش بیشتری رو تجربه کنند تا موفق تر باشند توصیه ما انتخاب همین دوره همراه با کلاس می باشد.
بعد از پرداخت هزینه، آدرس کانال و نحوه عضویت در سامانه کوئرا قابل مشاهده میباشد. در این روش هیچ گونه ویدئویی به محض پرداخت برایتان ارسال نخواهد شد. بلکه ویدئوها بصورت هفتگی از طریق سامانه کوئرا و پست الکترونیکی ثبت شده برایتان ارسال میگردد.
در این روش مدرس دوره در طی دوره تمریناتی را در اختیار شما قرار خواهد داد و تصحیح خواهد نمود و همراه شما در کل دوره خواهد بود. مدت زمان این دوره 13 هفته میباشد که از هفته اول آذر شروع خواهد شد. توصیه ما بر مخاطبینی که تمایل دارند بیشتر خود را درگیر این دوره نمایند انتخاب همین روش میباشد.
📘 حجم کل جلسات : 3 GB
📘 زمان کل جلسات : 16 ساعت
📘 میزان تخفیف : 10000 تومان
📘 کد تخفیف (با حروف کوچک وارد کنید) : mchntwo




برای دانلود راهنمای سریع (Cheat Sheet) دستورهای پایتون برای علم داده میتوانید از طریق لینک زیر اقدام کنید.
به راحتی با آموزشهای آنلاین و ویدئویی شما میتوانید دورههای مرتبط با زبان برنامهنویسی پایتون را یاد بگیرید، در آموزشهای آنلاین هزینه رفت و آمد کلاسهای حضوری و همچنین هزینههای بالای ثبتنام در کلاسهای حضوری را پرداخت نخواهید کرد. و منابع مطالعاتی همیشه در دسترس خواهد بود.
دوره های که تاکنون در وب سایت چالش پایتون منتشر شده است یا در حال انتشار می باشد در لیست زیر قرار گرفت است.
- دوره مقدماتی پایتون - رایگان
- دوره تکمیلی پایتون - منتشر شد
- دوره پردازش تصویر پایتون - منتشر شد
- دوره یادگیری ماشین پایتون - منتشر شد
ورکشاپهای چالش پایتون، ویدئوهای کوتاه یک الی سه قسمتی هستند که برای بخشی از یک موضوع خاص در نظر گرفته میشوند. پایه و اساس این ورکشاپها پیادهسازی پروژهها با برنامهنویسی پایتون میباشد.
لیست ورکشاپ ها:
- تشخیص چهره با پایتون - رایگان
- استگانوگرافی (نهان نگاری) با پایتون - منتشر شد
- تشخیص نوع بیماری با پایتون - منتشر شد
- تشخیص اشیاء (صورت انسان) با پایتون - منتشر شد
- تشخیص متن با پایتون - منتشر شد
- تشخیص صدا با پایتون - منتشر شد
