📗کار با متون در جملات
📕تقسیم جملات به کلمات و کلمات به کارکتر
📒پیدا کردن کلمات منحصر به فرد(حذف موارد تکراری)
📘کار با متن در سندهای فایل
![]() دریافت کدهای درس دوم
دریافت کدهای درس دوم
حجم: 3.08 کیلوبایت


📗کار با متون در جملات
📕تقسیم جملات به کلمات و کلمات به کارکتر
📒پیدا کردن کلمات منحصر به فرد(حذف موارد تکراری)
📘کار با متن در سندهای فایل
![]() دریافت کدهای درس دوم
دریافت کدهای درس دوم
حجم: 3.08 کیلوبایت
✅ کار با فایل های متنی بزرگ
🔹 اگر بخواهیم فایل متنی مثل یک فایل نوت پد رو با پسوند txt رو بخوانیم باید از دستور open استفاده کنیم. فرمت دستور open به این صورت است که ورودی اول باید نام فایل یا آدرس محلی که فایل متنی در آنجا قرار دارد، باشد. ورودی دوم مد r هست که برای خوندن استفاده میشه و ورودی سوم رو هم از utf8 استفاده میکنیم، دلیل گذاشتن این ورودی سوم اینه که اگر شما این ساختار رو مشخص نکنید پایتون در خروجی یکسری کارکترهای اضافی در ابتدا نمایش خواهد داد.مثال رو ببنیم:
>>> f = open('D:\Text mining\week-1\Lesson-2\humans.txt','r',encoding='utf-8-sig')
🔹 اگر بخواهیم فایل فوق رو بصورت خط به خط بخونیم باید از دستور readline بصورت زیر استفاده کنیم. (در برنامه نویسی انتهای هر خط با n/ مشخص میشه)
>>> f.readline()
'Python is an interpreted high-levelprogramming\n'
▪️نکته ای که در این بخش هست اینه که با هر بار اجرای دستور فوق یک خط خوانده می شود. دقت کنید که پایتون زمانی انتهای خط را تشخیص خواهد داد که دکمه اینتر زده شود.بنابراین اگر پارگراف نوشته شد اما فقط در انتهای پارگراف اینتر زده شد، تمام پارگراف را یک خط تشخیص خواهد داد.
🔹 خواندن کل فایل : برای اینکه مشخص کنیم از کجای فایل متن رو باید بخونیم میتونیم از تابع seek برای اینکار استفاده کنیم. دقت کنید که عبارت داخل پرانتر تابع seek اندیس شروع خوندن رو نشون میده که پیش فرض صفر خواهد بود. حالا ما در این مثال هم میخواهیم از ابتدا شروع کنیم کل فایل رو بخونیم، بنابراین داریم :
>>> f.seek(0)
0
>>> text9 = f.read()
>>> len(text9)
2672
▪️همانطور که در بالا میبینید کل فایل از اندیس صفر شروع به خوندن میکنیم و تعداد کارکترهای که داخل متنمون قرار داشت 2672 بود.
🔹حالا اگر بخواهیم کل فایل رو خط به خط جدا کنیم و در یک لیستی قرار بدهیم کافیه از تابع splitlines برای اینکار بصورت زیر استفاده کنیم
>>> text10 = text9.splitlines()
>>> len(text10)
21
>>> text10[0]
'Python is an interpreted high-levelprogramming'
▪️تعداد خطهای این فایل 21 بود و با اندیس میتونیم هر خطی که خواستیم در خروجی نمایش بدهیم.
✅ مثالهای گوناگون
🔹 تابع split بصورت پیش فرض رشته ها رو از طریق space یا همون فاصله جدا میکنه و کلمات رو استخراج میکنه، اما ما میتونیم داخل پرانتز کارکتر دلخواه خودمون رو بعنوان میعار جدا کردن در نظر بگیریم. مثال زیر رو ببنید:
>>> text4 = "ouagadougou"
>>> text5 = text4.split('ou')
>>> text5
['', 'agad', 'g', '']
▪️خوب در مثال بالا رشته رو بر اساس کارکتر ou جدا کرد.دقت کنید که ما text4 رو نمیتونیم بر اساس میعار فاصله جدا کنیم چون هیچ فاصله ای در این رشته وجود نداره و اگر داخل پرانتر دستور split خالی باشه به ارور خواهیم خورد.
🔹 در دوره مقدماتی در مورد لیست صحبت کردیم و اگر بخواهیم text4 رو تبدیل به لیست کنیم کارکتر به کارکتر داخل یک لیست برامون قرار میده.
>>> list(text4)
['o', 'u', 'a', 'g', 'a', 'd', 'o', 'u', 'g', 'o', 'u']
🔹با استفاده از حلقه for هم امکان ایجاد لیست فوق وجود داره، مثال رو ببنید.
>>> [c for c in text4]
['o', 'u', 'a', 'g', 'a', 'd', 'o', 'u', 'g', 'o', 'u']
🔹 حالا اگر بخواهیم دوباره ou رو به text5 متصل کنیم از دستور join برای اینکار استفاده میکنیم.و نحوه استفاده بصورت زیر خواهد بود
>>> 'ou'.join(text5)
'ouagadougou'

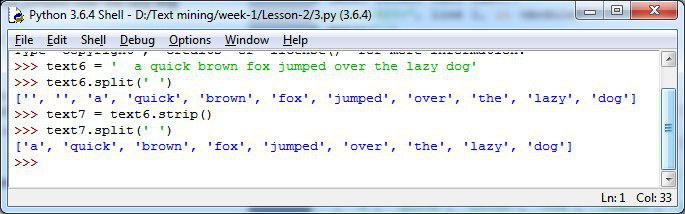
🔹یک رشته جدید تو این مثال خواهیم زد که ابتدای رشته دوتا فاصله وجود داره؛ ما اول میاییم با دستور split کلمات رو جدا میکنیم و اتفاقی که میفته فاصله های ابتدایی رو بعنوان یک کلمه مجزا درنظر میگیره
>>> text6 = ' a quick brown fox jumped over the lazy dog'
>>> text6.split(' ')
['', '', 'a', 'quick', 'brown', 'fox', 'jumped', 'over', 'the', 'lazy', 'dog']
🔹حالا اگر بخواهیم این فاصله های اضافی رو برداریم و با توجه به اینکه این موضوع برای مباحث متن کاوی مهم هست که موارد اضافه رو حذف کنیم از دستور strip برای اینکار استفاده خواهیم کرد.
>>> text7 = text6.strip()
>>> text7.split(' ')
['a', 'quick', 'brown', 'fox', 'jumped', 'over', 'the', 'lazy', 'dog']
▪️همانطور که در بالا مشاهده میکنیم دیگر فاصله ها در لیست ما قرار ندارند.
مثال دستور find و replace
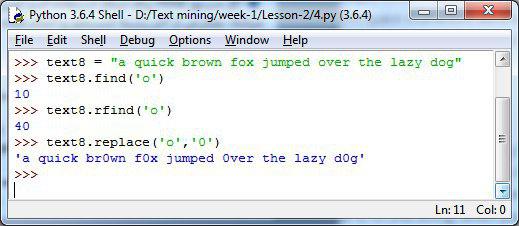
🔹 در متن جدید میخواهیم کارکتر o رو پیدا کنیم اگر از دستور find استفاده کنیم اولین کارکتر o در متن رو پیدا میکنه و اندیسش رو بعنوان خروجی برمیگردونه. (اندیس در پایتون از صفر شروع میشه)
>>> text8 = "a quick brown fox jumped over the lazy dog"
>>> text8.find('o')
10
🔹 اگر دستور rfind برای اینکار استفاده کنید آخرین کارکتر o در رشته رو پیدا میکنه، بعبارتی از آخر رشته جستجو رو انجام میده.
>>> text8.rfind('o')
40
🔹 و برای جایگزینی کارکتر o با مقدار صفر (0) میتونیم از دستور replace بصورت زیر استفاده کنیم
>>> text8.replace('o','0')
'a quick br0wn f0x jumped 0ver the lazy d0g'
🏅به دو نفر برتر این مسابقه یکی از آموزش های چالش پایتون با انتخاب خودشان، به رایگان اهدا خواهد شد.
▪️فقط اعضای کلاس چالش پایتون در سامانه کوئرا میتوانند در این مسابقه نوروزی شرکت کنند. اگر عضو نشدید از طریق راهنمای زیر عضو شوید:
https://t.me/pythonchallenge/528
🔹مسابقه راس ساعت 13 امروز شروع خواهد شد و ساعت 23 به اتمام خواهد رسید. در شرایط مساوی زمان در تعیین رتبه تاثیرگذار می باشد.

✅ معرفی توابع پایتون برای رشته ها
🔹 تو تایپیک قبل در مورد اینکه چه توابعی برای کلمات در پایتون وجود داره رو گفتیم، الان میخواهیم توابع رو برای رشته ها بگیم. باز یک تعریف کلی داریم و مثال ها رو تو بخش های بعدی خواهیم زد.
1️⃣ تبدیل کردن به حروف کوچک و بزرگ رشته ها و همچنین تبدیل یک رشته به حالت titlecase
s.upper() ; s.lower() ; s.title()
🔹 نکته ای که در توابع بالا نسبت به توابع مربوط به کلمات هست اینه که ما اینجا is رو نداریم. و در واقع اینجا نماییم بررسی کنیم که، آیا رشته ما با حروف بزرگ تشکیل شده یا کوچک.بلکه اینجا کار تبدیل کردن رو انجام خواهیم داد.
2️⃣ جدا کردن کلمات که بارها تو اسلایدهای قبل ازش استفاده کردیم و در بخش های بعدی هم استفاده خواهیم کرد.
s.split()
3️⃣حالا اگر بخواهیم یک سند رو یا یک پارگراف رو بر اساس خطوط جدا کنیم میتونیم از تایع زیر استفاده کنیم.
s.splitlines()
🔹نکته ای که اینجا هست و شاید براتون سوال باشه اینه چطور میتونیم در IDLE پایتون، یک رشته رو در چند خط بنویسیم.برای اینکار کافیه کوتیشن که برای رشته در ابتدا و انتهاش بکار برده میشه بجای یکی از سه تا استفاده کنیم.
>>> s="""how are
you today"""
>>> s
'how are\nyou today'
4️⃣ تابع join برای اتصال رشته ها به هم هست که ما تو بخش های بعدی مثال های خواهیم زد.
s.join()
5️⃣ تابع بعدی برای حذف می باشد وقتی از strip استفاده میکنیم و داخل پرانتر کارکتری رو وارد میکنیم سبب میشه که اون کارکتر از کل رشته حذف بشه و اگر از rsrtip استفاده کنیم از انتهای رشته فقط یک موردش حذف خواهد شد . حالا مثالهای رو در بخش های بعدی خواهید دید.
s.strip() ; s.rstrip()
6️⃣ دستور بعدی برای یافتن یک رشته یا کارکتر داخل رشته دیگه استفاده میشه.اگر عبارت داخل پرانتر در رشته بود اندیس شروع اون عبارت رو بعنوان خروجی برمیگردونه. اما یک تفاوت اساسی در rfind وجود داره اینه که در این تابع حتما باید کلمه مورد نظر بصورت جدا باشه.ما برای این مورد خاص همینجا یک مثال میزنیم
s.find() ; s.rfind()
مثال
>>> s1 = "this is really a string example....wow!!!";
>>> s2 = "is";
>>> s1.find(s2)
2
>>> s1.rfind(s2)
5
🔸 خوب تو مثال بالا کاملا تفاوت این دو تابع مشخصه که ما در rfind کلماتی رو پیدا میکنیم که مجزا باشند و ترکیب شده با حروف دیگری نباشند.
7️⃣ آخرین دستور این بخش دستور جایگزینی یا همون replace هست که میاد تو رشته میگرده و اگر عبارت u وجود داشت با v جایگزین خواهد کرد.
s.replace(u,v)
🔘 در آخر باید بگم حتما مثالهای گوناگونی برای این بخش خواهیم زد. تا تمام این توابع، کامل توضیح داده باشیم
✅ معرفی توابع پایتون برای کلمات
🔹 در این بخش یک تعریف کلی از این توابع خواهیم داشت و در بخش های بعدی مثال های رو بیان خواهیم کرد.
1️⃣ کلماتی که با یک حرف خاص شروع خواهند شد.
s.startswith()
2️⃣ کلماتی که با یک حرف خاص به اتمام می رسند.(در بخش قبل مثال زدیم)
s.endswith()
3️⃣ بررسی وجود یک کلمه در داخل رشته با دستور in
T in s
4️⃣ تشخیص حروف بزرگ و کوچک در کلمات و همچنین یافتن کلماتی که با حرف بزرگ شروع خواهند شد.
s.isupper() ; s.islower() ; s.istitle()
5️⃣تشخیص حروف الفبا یا عدد.
s.isalpha() ; s.isdigit() ; s.isalnum()
▪️تابع اول برای تشخیص حروف الفبا در رشته می باشد که شامل عدد و کارکترهای خاص نباشد.
▪️تابع دوم تشخیص عدد در رشته می باشد.
▪️و تایع سوم میتونه شامل الفبا و عدد باشد اما کارکترهای خاص مثل فاصله و ... را شامل نخواهد شد.
🔸 خروجی سه تا تابع فوق True یا False می باشد.
🔹 در بخش های بعدی برای هر یک از موارد بالا مثال های خواهیم زد.
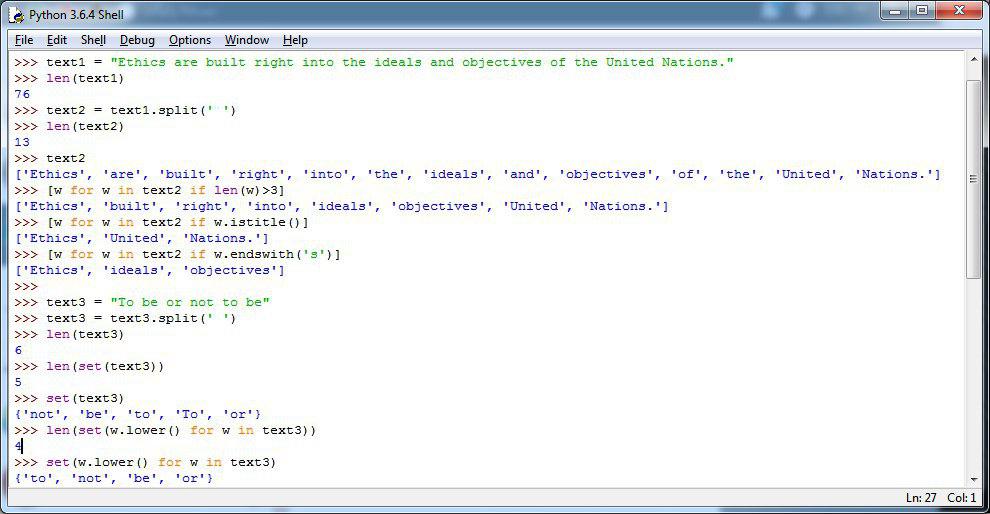
✅ پیدا کردن کلماتی که یکبار در جمله تکرار شدند یا حذف کلمات تکراری در جملات
▪️ پایتون تابعی به نام set داره که میاد کلماتی که در جمله تکرار شدند رو حذف میکنه. ما در اینجا یک مثال جدید خواهیم زد:
>>> text3 = "To be or not to be"
>>> text3 = text3.split(' ')
>>> len(text3)
6
▪️همانطور که در کد بالا مشاهده میکنیم جمله ما در ابتدا 6 کلمه بود و دو از این کلمات تکراری هست یکی to و دیگری be. حالا اگر بخواهیم با استفاده از set این کلمات تکراری رو حذف کنیم ببنیم چه اتفاقی خواهد افتاد:
>>> len(set(text3))
5
>>> set(text3)
{'not', 'be', 'to', 'To', 'or'}
▪️همانطور که در بالا مشاهده میکنید کد فوق be رو حذف کرد اما to رو نه. قبلا تو پایتون مقدماتی تاکید کردیم که پایتون برای حروف بزرگ و کوچک تفاوت قائل هستش و این دلیل حذف نشدن کلمه to و To هست.خوب راه حل چیه؟
▪️ راه حل اینه که ابتدا بیاییم کل جمله رو تبدیل به حروف کوچک کنیم سپس کلمات تکراری رو حذف کنیم. بوسیله کد زیر:
>>> len(set(w.lower() for w in text3))
4
>>> set(w.lower() for w in text3)
{'to', 'not', 'be', 'or'}
▪️ ابتدا توسط تابع lower تمام حروف رو در یک حلقه for کوچک کردیم بعد از تابع set برای حذف تکراریها استفاده میکنه و در نهایت هم طولش رو نمایش میده و در خط بعد کارکترهای یکتا رو چاپ میکنه.
برای نمایش تصویر در سایز بزرگتر بر روی تصویر کلیک کنید.