📗عبارتهای منظم چی هستند
📕متاکارکترهای مربوط به عبارت های منظم
📒ساختن یک عبارت منظم برای تاریخ
![]() دریافت کدهای درس سوم
دریافت کدهای درس سوم
حجم: 1.02 کیلوبایت

📗عبارتهای منظم چی هستند
📕متاکارکترهای مربوط به عبارت های منظم
📒ساختن یک عبارت منظم برای تاریخ
![]() دریافت کدهای درس سوم
دریافت کدهای درس سوم
حجم: 1.02 کیلوبایت
✅ مثالهای گوناگون
🔹 تابع split بصورت پیش فرض رشته ها رو از طریق space یا همون فاصله جدا میکنه و کلمات رو استخراج میکنه، اما ما میتونیم داخل پرانتز کارکتر دلخواه خودمون رو بعنوان میعار جدا کردن در نظر بگیریم. مثال زیر رو ببنید:
>>> text4 = "ouagadougou"
>>> text5 = text4.split('ou')
>>> text5
['', 'agad', 'g', '']
▪️خوب در مثال بالا رشته رو بر اساس کارکتر ou جدا کرد.دقت کنید که ما text4 رو نمیتونیم بر اساس میعار فاصله جدا کنیم چون هیچ فاصله ای در این رشته وجود نداره و اگر داخل پرانتر دستور split خالی باشه به ارور خواهیم خورد.
🔹 در دوره مقدماتی در مورد لیست صحبت کردیم و اگر بخواهیم text4 رو تبدیل به لیست کنیم کارکتر به کارکتر داخل یک لیست برامون قرار میده.
>>> list(text4)
['o', 'u', 'a', 'g', 'a', 'd', 'o', 'u', 'g', 'o', 'u']
🔹با استفاده از حلقه for هم امکان ایجاد لیست فوق وجود داره، مثال رو ببنید.
>>> [c for c in text4]
['o', 'u', 'a', 'g', 'a', 'd', 'o', 'u', 'g', 'o', 'u']
🔹 حالا اگر بخواهیم دوباره ou رو به text5 متصل کنیم از دستور join برای اینکار استفاده میکنیم.و نحوه استفاده بصورت زیر خواهد بود
>>> 'ou'.join(text5)
'ouagadougou'

🔹یک رشته جدید تو این مثال خواهیم زد که ابتدای رشته دوتا فاصله وجود داره؛ ما اول میاییم با دستور split کلمات رو جدا میکنیم و اتفاقی که میفته فاصله های ابتدایی رو بعنوان یک کلمه مجزا درنظر میگیره
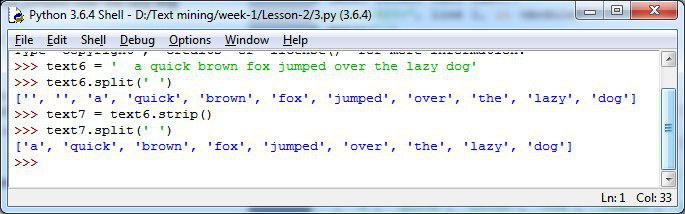
>>> text6 = ' a quick brown fox jumped over the lazy dog'
>>> text6.split(' ')
['', '', 'a', 'quick', 'brown', 'fox', 'jumped', 'over', 'the', 'lazy', 'dog']
🔹حالا اگر بخواهیم این فاصله های اضافی رو برداریم و با توجه به اینکه این موضوع برای مباحث متن کاوی مهم هست که موارد اضافه رو حذف کنیم از دستور strip برای اینکار استفاده خواهیم کرد.
>>> text7 = text6.strip()
>>> text7.split(' ')
['a', 'quick', 'brown', 'fox', 'jumped', 'over', 'the', 'lazy', 'dog']
▪️همانطور که در بالا مشاهده میکنیم دیگر فاصله ها در لیست ما قرار ندارند.
مثال دستور find و replace
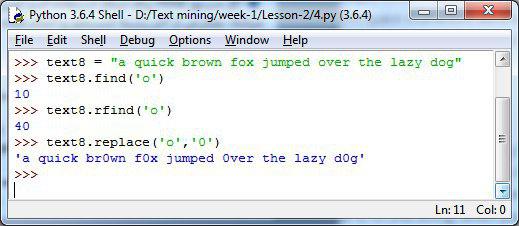
🔹 در متن جدید میخواهیم کارکتر o رو پیدا کنیم اگر از دستور find استفاده کنیم اولین کارکتر o در متن رو پیدا میکنه و اندیسش رو بعنوان خروجی برمیگردونه. (اندیس در پایتون از صفر شروع میشه)
>>> text8 = "a quick brown fox jumped over the lazy dog"
>>> text8.find('o')
10
🔹 اگر دستور rfind برای اینکار استفاده کنید آخرین کارکتر o در رشته رو پیدا میکنه، بعبارتی از آخر رشته جستجو رو انجام میده.
>>> text8.rfind('o')
40
🔹 و برای جایگزینی کارکتر o با مقدار صفر (0) میتونیم از دستور replace بصورت زیر استفاده کنیم
>>> text8.replace('o','0')
'a quick br0wn f0x jumped 0ver the lazy d0g'
✅ معرفی توابع پایتون برای کلمات
🔹 در این بخش یک تعریف کلی از این توابع خواهیم داشت و در بخش های بعدی مثال های رو بیان خواهیم کرد.
1️⃣ کلماتی که با یک حرف خاص شروع خواهند شد.
s.startswith()
2️⃣ کلماتی که با یک حرف خاص به اتمام می رسند.(در بخش قبل مثال زدیم)
s.endswith()
3️⃣ بررسی وجود یک کلمه در داخل رشته با دستور in
T in s
4️⃣ تشخیص حروف بزرگ و کوچک در کلمات و همچنین یافتن کلماتی که با حرف بزرگ شروع خواهند شد.
s.isupper() ; s.islower() ; s.istitle()
5️⃣تشخیص حروف الفبا یا عدد.
s.isalpha() ; s.isdigit() ; s.isalnum()
▪️تابع اول برای تشخیص حروف الفبا در رشته می باشد که شامل عدد و کارکترهای خاص نباشد.
▪️تابع دوم تشخیص عدد در رشته می باشد.
▪️و تایع سوم میتونه شامل الفبا و عدد باشد اما کارکترهای خاص مثل فاصله و ... را شامل نخواهد شد.
🔸 خروجی سه تا تابع فوق True یا False می باشد.
🔹 در بخش های بعدی برای هر یک از موارد بالا مثال های خواهیم زد.

✅ پیدا کردن کلماتی که یکبار در جمله تکرار شدند یا حذف کلمات تکراری در جملات
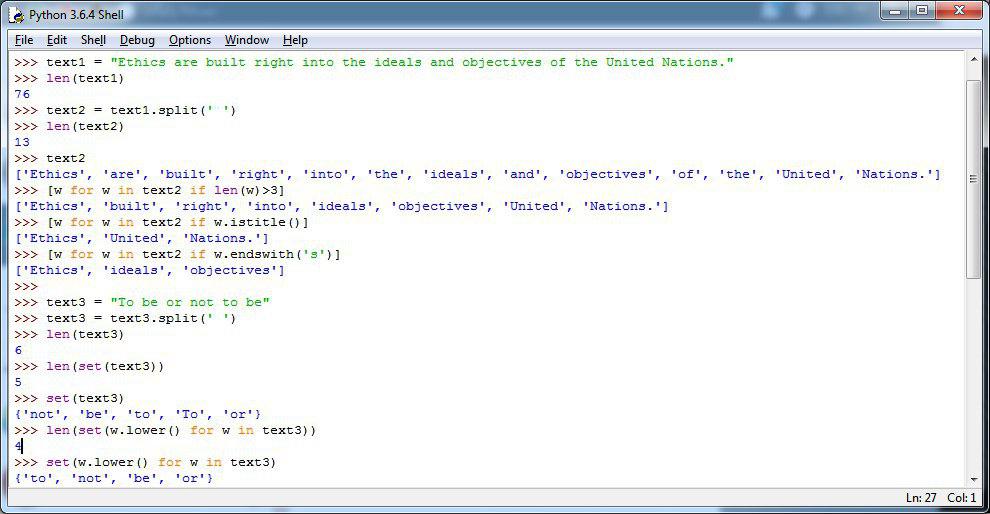
▪️ پایتون تابعی به نام set داره که میاد کلماتی که در جمله تکرار شدند رو حذف میکنه. ما در اینجا یک مثال جدید خواهیم زد:
>>> text3 = "To be or not to be"
>>> text3 = text3.split(' ')
>>> len(text3)
6
▪️همانطور که در کد بالا مشاهده میکنیم جمله ما در ابتدا 6 کلمه بود و دو از این کلمات تکراری هست یکی to و دیگری be. حالا اگر بخواهیم با استفاده از set این کلمات تکراری رو حذف کنیم ببنیم چه اتفاقی خواهد افتاد:
>>> len(set(text3))
5
>>> set(text3)
{'not', 'be', 'to', 'To', 'or'}
▪️همانطور که در بالا مشاهده میکنید کد فوق be رو حذف کرد اما to رو نه. قبلا تو پایتون مقدماتی تاکید کردیم که پایتون برای حروف بزرگ و کوچک تفاوت قائل هستش و این دلیل حذف نشدن کلمه to و To هست.خوب راه حل چیه؟
▪️ راه حل اینه که ابتدا بیاییم کل جمله رو تبدیل به حروف کوچک کنیم سپس کلمات تکراری رو حذف کنیم. بوسیله کد زیر:
>>> len(set(w.lower() for w in text3))
4
>>> set(w.lower() for w in text3)
{'to', 'not', 'be', 'or'}
▪️ ابتدا توسط تابع lower تمام حروف رو در یک حلقه for کوچک کردیم بعد از تابع set برای حذف تکراریها استفاده میکنه و در نهایت هم طولش رو نمایش میده و در خط بعد کارکترهای یکتا رو چاپ میکنه.
برای نمایش تصویر در سایز بزرگتر بر روی تصویر کلیک کنید.
✅ پیدا کردن کلمات با ویژگی های خاص
1️⃣ اگر بخواهیم کلماتی که بیش از سه حرف داشته باشند رو، کلمات طولانی بنامیم. با استفاده از حلقه for و تابع len میتوانیم این کلمات رو از جمله فوق استخراج کنیم.
>>> [w for w in text2 if len(w)>3]
['Ethics', 'built', 'right', 'into', 'ideals', 'objectives', 'United', 'Nations.']
▪️ همانطور که در نتیجه مشاهده میکنید تمام کلمات بیش از سه حرف هستند
2️⃣ معمولا در زبان انگلیسی حرف اول اسامی و یا اولین کلمه موجود در جمله با حروف بزرگ نوشته می شود. حالا اگر بخواهیم این کلمات را از جمله استخراج کنیم؛ تابع ()istitle در پایتون اینکار رو برامون انجام میده.
>>> [w for w in text2 if w.istitle()]
['Ethics', 'United', 'Nations.']
▪️ تمام کلماتی که با کارکتر بزرگ شروع میگردند را نمایش داد.
3️⃣ در پایتون اگر بخواهیم کلماتی که به یک کارکتر خاص ختم می شوند رو نمایش بدهیم کافیه از تابع ()endswith استفاده کنیم. داخل پرانتز کارکتری که میخواهیم بهش ختم بشه رو وارد میکنیم. مثال زیر رو ببینید.
>>> [w for w in text2 if w.endswith('s')]
['Ethics', 'ideals', 'objectives']
▪️ نمایش تمام کلماتی که به s ختم می شوند
سازمان دهی دانش و متن کاوی، در بازیابی دقیق اطلاعات کاربرد بسیاری دارند. از این رو، متن کاوی می تواند کارکردهای بسیاری در بهبود سازمان دهی دانش داشته باشد. اگرچه متن کاوی، به ویژه در بخش یادگیری ماشینی و به دست آوردن اسناد و نمونه های آموزشی، نیازمند نظام های اصطلاح نامه، طبقه بندی، فهرست نویسی و نمایه سازی است، سازمان دهی برای تسریع کار خود، نیازمند فنون متن کاوی و نتیجه کارهای آن خواهد بود تا هم سرعت کار خویش را افزایش دهد و هم هزینه هایش را بکاهد. در این نوشتار، به کارکردهای متن کاوی در حوزه سازمان دهی دانش پرداخته خواهد شد.