📗در این درس با کتابخانه pandas برای پردازش داده های متنی آشنا شدیم
📕این کتابخانه روشها و متدهای زیادی را برای پردازش داده های متنی دارد که با استفاد این روش ها و ترکیب ها قادر خواهیم بود برخی از پرازش های متنی بسیار قدرتمند رو با pandas انجام دهیم.
مجله خبری برنامهنویسی پایتون
مرکز آموزش و رقابت برنامه نویسی پایتون

زبان پایتون (Python) در سال ۱۹۹۱ توسط یک برنامهنویس هلندی به نام گیدو ون روسوم (Guido van Rossum) ابداع شد و از آن زمان تا کنون رشد قابل ملاحظهای را شاهد بوده است.
اگر چه وی در آن زمان گفته بود: «من به هیچ وجه قصد ندارم زبانی بسازم که به طور گسترده مورد استفاده قرار بگیرد» ولی اکنون و با گذشت نزدیک به سه دهه از آن تاریخ، پایتون تقریباً تمام رقبای خود را کنار زده و به اندازهای محبوبیت یافته که حتی افراد مبتدی نیز کدنویسی را با آن شروع میکنند.
در یک سال گذشته، «Python» یکی از کلماتی بود که شهروندان آمریکایی بسیار زیاد در گوگل جستجو کردهاند، حتی بیشتر از نام ستارههای تلویزیونی.
طبقه بندی موضوعی
-
برنامه نویسی
(۳۳) -
اخبار
(۲۱) -
جشنواره تخفیف
(۶) -
استخدام
(۴) -
یادگیری ماشین با پایتون
(۳) -
مطالب آموزشی
(۵) -
متن کاوی
(۲۰) -
چالش
(۱) -
کتاب
(۱) -
کتابچه
(۳) -
وبینار
(۱)
کلمات کلیدی
آموزش پایتون
متن کاوی با پایتون
python
متن کاوی
یادگیری ماشین
پایتون
text mining
استخدام برنامه نویس پایتون
یادگیری ماشین با پایتون
پایتون در یادگیری عمیق
Pandas
پایتون برای علم داده
استخدام
محبوب ترین زبان برنامه نویسی
هوش مصنوعی
عبارت منظم در پایتون
replace
استخراج متن در پایتون
کد تخفیف یلدا
یادگیری عمیق
وب سایت آموزشی پایتون
NumPy
Matplotlib
Cheat Sheet
جشنواره تخفیف
پردازش تصویر
ریاضی
jupyter notebook
وبینار
ات ساین
بایگانی
- فروردين ۱۳۹۹ (۲)
- اسفند ۱۳۹۸ (۳)
- بهمن ۱۳۹۸ (۱)
- دی ۱۳۹۸ (۳)
- آذر ۱۳۹۸ (۸)
- شهریور ۱۳۹۸ (۳)
- تیر ۱۳۹۸ (۲)
- خرداد ۱۳۹۸ (۱)
- ارديبهشت ۱۳۹۸ (۳)
- فروردين ۱۳۹۸ (۷)
- اسفند ۱۳۹۷ (۴)
- بهمن ۱۳۹۷ (۱)
- دی ۱۳۹۷ (۱)
- آذر ۱۳۹۷ (۴)
- آبان ۱۳۹۷ (۱۸)
- مهر ۱۳۹۷ (۱۴)
آخرین مطالب
-
۹۹/۰۱/۱۱تخفیف بزرگ چالش پایتون در سال 99
-
۹۸/۱۰/۱۲کتابچه پایتون : کتابخانه scrappy
-
۹۸/۱۰/۱۰کتابچه پایتون : کتابخانه PIL
پیوندها

متد بعدی extract می باشد که میخواهیم رشته های رو استخراج کنیم که منطبق بر یک سری گروههای داخل پرانتز باشد. (مجددا تاکید میکنیم عبارت داخل پرانتز را بعنوان یک گروه در نظر میگیریم.)
در رشته ورودی اگر دقت کنیم میبینم زمان ها بصورت ساعت و دقیقه می باشد. تمام دقایق در این مثال ما بصورت دو رقمی بوده اما ساعت ممکن است یک رقمی یا دو رقمی باشد. پس عبارت منظم زیر رو برای پیدا کردن زمان در رشته و مجزا کردن آن در یک ستون دیگر استفاده میکنیم.
df['text'].str.extract(r'(\d?\d):(\d\d)')
0 1
0 2 45
1 11 30
2 7 00
3 11 15
4 08 1
عبارت منظم بالا در داخل یک پرانتز دو رقم رو در نظر خواهد گرفت اما علامت سوالی که در پرانتز اول وجود داره به این دلیل هست که اعلام کنه رقم اول میتونه باشه و میتونه هم نباشه که این مورد برای ساعت کاربرد داره.
نکته ای که وجود داره اینه که در رشته پنجم ما دو تا زمان داشتیم اما فقط اولی رو چاپ کرد. برای این که مشکل رو رفع کنیم از متد extractall استفاده میکنیم و عبارت منظم رو هم طوری تغییر میدهیم که علامت pm یا am بعد ساعت هم در خروجی چاپ گردد.
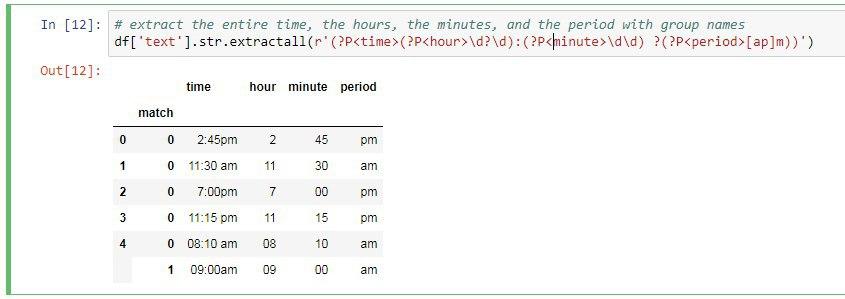
حالا ما چهار تا گروه میخواهیم ایجاد کنیم گروه اول کل عبارت رو چاپ میکنه در واقع زمان رو چاپ میکنه و برای همین باید کل عبارت داخل پرانتز قرار بگیره. گروه دوم ساعت، گروه سوم دقیقه و گروه چهارم هم صبح یا عصر بودن رو چاپ خواهد کرد.
df['text'].str.extractall(r'((\d?\d):(\d\d) ?([ap]m))
خروجی برنامه در تصویر بعدی قرار دارد.
اما یک نکته وجود علامت سوال قبل از مشخص کردن صبح یا عصر بودن هست.دلیل این مورد بخاطر وجود فاصله بین ساعت و pm یا am هست که در بعضی از رشته ها این فاصله وجود داره و در بعضی ها نبود و ما هم برای همین یک اسپس علامت سوال در نظر گرفتیم تا وجودش الزامی نباشه و اختیاری باشه.

حالا در انتها اگر بخواهیم برای ستون ها ما نامی رو مشخص کنیم کافیه از همان نام گروه برای اینکار استفاده کنیم. برای ایجاد نام گروه از دستور زیر استفاده میکنیم:
?P<GroupName>
و بجای GroupName هر نامی که دوست داشتید میتوانید قرار بدهید.
دقت کنید محل قرار گرفتن نام گروه بعد از پرانتز باز همان گروه می باشد.
df['text'].str.extractall(r'(?P<time>(?P<hour>\d?\d):(?P<minute>\d\d)?(?P<period>[ap]m))')
در مثال بعدی میخواهیم از دستوری برای جایگزینی استفاده کنیم بعنوان مثال هر جا روزی در هفته وجود داشت بجای آن روز، سه تا علامت سوال قرار بدهیم.
نکته ای که اینجا وجود داره اینه که تمام روزهای هفته ما به کلمه day ختم خواهد شد. در درس قبل گفتیم w برای تمام کارکتر ها استفاده میشه و b هم برای مشخص کردن مرز کلمه یا بعبارت بهتر پیدا کردن یک تطابق در ابتدا یا انتهای کلمه استفاده خواهد شد.
پس میتوانیم از عبارت نامنظم زیر و متد str.replace برای هدفمون استفاده کنیم:
df['text'].str.replace(r'\w+day\b', '???')
0 ???: The doctor's appointment is at 2:45pm.
1 ???: The dentist's appointment is at 11:30 am.
2 ???: At 7:00pm, there is a basketball game!
3 ???: Be back home by 11:15 pm at the latest.
4 ???: Take the train at 08:10 am, arrive at 09:..
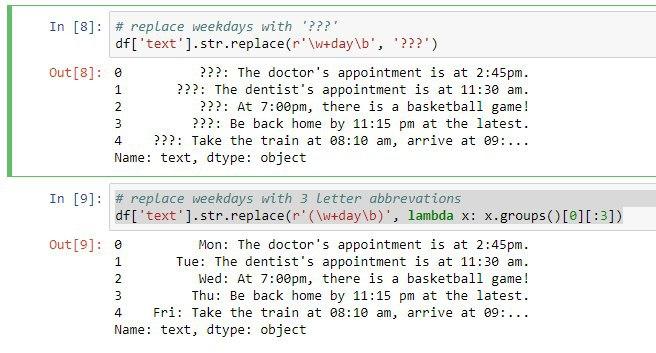
حالا اگر فرض بر این باشه بخواهیم تغییر در رشته ایجاد کنیم که بر مبنای کلمه مورد نظر باشه از متدهای replace و lambda استفاده خواهیم کرد. دقت کنید ما متد لامبدا رو در دوره مقدماتی توضیح داده بودیم.
حالا در این مثال میخواهیم بجای روزهای هفته، فقط سه حرف ابتداییش در خروجی قرار بگیره. مثلا بجای Monday عبارت Mon چاپ گردد.
df['text'].str.replace(r'(\w+day\b)', lambda x: x.groups()[0][:3])
0 Mon: The doctor's appointment is at 2:45pm.
1 Tue: The dentist's appointment is at 11:30 am.
2 Wed: At 7:00pm, there is a basketball game!
3 Thu: Be back home by 11:15 pm at the latest.
4 Fri: Take the train at 08:10 am, arrive at 09:..
در کد فوق تابعی که با استفاده از لامبدا مشخص شده برای جدا کردن سه حرف اول روزها هفته است.
در واقع الگوی ما توسط عبارت منظم پیدا میشه و وقتی که داخل پرانتز قرار میدهیم اون رو تبدیل به یک گروه خواهیم کرد سپس توسط replace با سه حرف اول روزهای هفته جایگزین میکنیم.
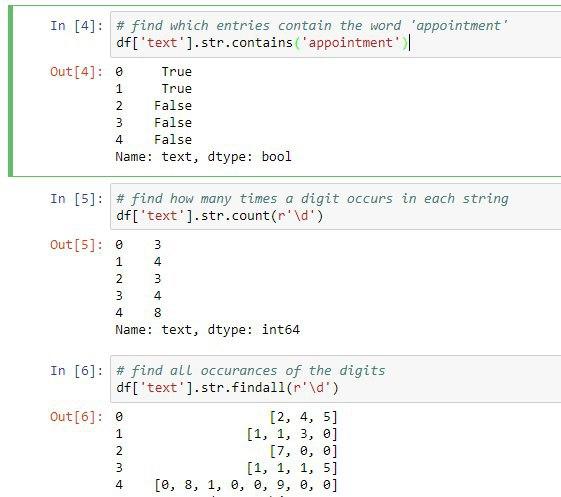
برای اینکه متوجه گردیم رشته ورودی ما شامل یک کلمه خاص یا یک الگو می باشد میتوانیم از متد str.contains استفاده کنیم. مثال زیر رو ببنید:
df['text'].str.contains('appointment')
0 True
1 True
2 False
3 False
4 False
خوب در نتیجه مشخص شد رشته اول و دوم کلمه apppintment رو شامل میشود
متد بعدی برای str پیدا کردن تعداد الگوی خاصی در یک رشته می باشد. برای اینکار از تابع str.count استفاده میکنیم. در این مثال میخواهیم بدانیم چند عدد داخل یک رشته قرار دارد.
همانطور که در درس قبلی گفتیم از d برای پیدا کردن ارقام استفاده میکنیم.
df['text'].str.count(r'\d')
0 3
1 4
2 3
3 4
4 8
اگر به رشته ابتدایی ما توجه کنید مشاهده میکنید پنجمین رشته ما شامل 8عدد می باشد.
حالا اگر بخواهیم تعداد عددهای داخل یک رشته رو پیدا کنیم و بصورت لیست نمایش دهیم میتوانیم از متد str.findall برای اینکار استفاده کنیم
df['text'].str.findall(r'\d')
0 [2, 4, 5]
1 [1, 1, 3, 0]
2 [7, 0, 0]
3 [1, 1, 1, 5]
4 [0, 8, 1, 0, 0, 9, 0,]
اگر بخواهیم زمان رو بصورت ساعت و دقیقه در پرانتز بصورت جداگانه قید کنیم کافیه عبارت منظم مربوط را بصورت گروه بندی شده با استفاده از پرانتز استفاده کنیم
df['text'].str.findall(r'(\d?\d):(\d\d)')
دراین درس میخواهیم نگاهی به داده های متنی و کار با کتابخانه pandas بپردازیم.
ابتدا بصورت زیر یک داده متنی معرفی خواهیم کرد .و قبل از معرفی داده، کتابخانه pandas رو ایمپورت میکنیم:
import pandas as pd
time_sentences = ["Monday: The doctor's appointment is at 2:45pm.",
"Tuesday: The dentist's appointment is at 11:30 am.",
"Wednesday: At 7:00pm, there is a basketball game!",
"Thursday: Be back home by 11:15 pm at the latest.",
"Friday: Take the train at 08:10 am, arrive at 09:00am."]
برای اینکه برای ستون این داده متنی، اسمی رو قرار بدهیم از تابع DataFrame بصورت زیر استفاده میکنیم
df = pd.DataFrame(time_sentences, columns=['text'])
df
در حال حاضر داده ما شامل یک ستون هست که هر سطر آن یک متن می باشد و هر ورودی ما شامل یک روز در هفته و همچنین یک یا دو ساعت و دقیقه در بین متن می باشد

❇️ با استفاده از ویژگی str میتوانیم به مجموعه ای از روش های پردازش رشته دسترسی پیدا کنیم.
برای مثال متد str.len نشان دهنده طول متن یا همان تعداد کارکترهای هر رشته می باشد.
df['text'].str.len()
دستور بالا برای ستون text از رشته ورودی ، طول هر رشته را محاسبه میکند و در خروجی چاپ میکند. دقت کنید این ستون شامل 5 سطر می باشد و برای هر سطر بصورت جداگانه تعداد کارکترها را نمایش خواهد داد.
0 46
1 50
2 49
3 49
4 54
❇️ حالا اگر بخواهیم بجای تعداد کارکتر، تعداد کلمات رو مشخص کنیم. کافیه ابتدا با متد str.split کلمات یک متن رو با استفاده فاصله بین کلمات جدا کنیم سپس برای محاسبه طول اقدام کنیم:
df['text'].str.split().str.len()
0 7
1 8
2 8
3 10
4 10
پس برای مثال رشته اول شامل 7 کلمه و 46 کارکتر می باشد.

در درس چهارم تصمیم داریم وارد یک محیط جدید کدنویسی به نام jupyter notebook شویم و کدهامون رو تو این محیط اجرا کنیم.
طریقه نصب و کار کردن تو این محیط رو قبلا در دوره یادگیری ماشین بصورت ویدئویی ضبط کرده بودیم و شما میتونید بصورت رایگان از طریق لینک زیر بهش دسترسی داشته باشید.
📗عبارتهای منظم چی هستند
📕متاکارکترهای مربوط به عبارت های منظم
📒ساختن یک عبارت منظم برای تاریخ
![]() دریافت کدهای درس سوم
دریافت کدهای درس سوم
حجم: 1.02 کیلوبایت
عبارت های منظم برای تاریخ ها
تاریخ ها معمولا به شکل متنوعی نوشته خواهند شد. بعنوان مثال اگر بخواهیم بنویسیم 23 اکتبر 2018 میتوانیم به هر یک از صورتهای پایین بنویسیم:
23-10-2018
23/10/2018
23/10/18
10/23/2018
23 oct 2018
23 october 2018
oct 23, 2018
october 23, 2018
عبارت منظمی که میتوانیم برای تاریخ بنویسیم تا مورد اول، دوم و چهارم رو پوشش بده میتونه به این صورت باشه:
\d{2}[/-]\d{2}[/-]\d{4}
بعنوان مثال رشته زیر رو در نظر بگیرید: (n/ اشاره به خط بعد دارد.)
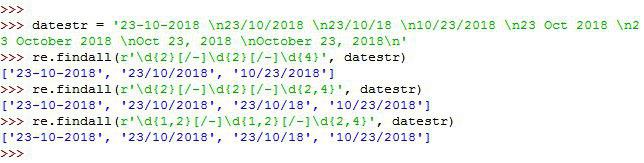
» datestr = '23-10-2018 \n23/10/2018 \n23/10/18 \n10/23/2018 \n23 oct 2018 \n23 october 2018 \noct 23, 2018 \noctober 23, 2018\n'
» re.findall(r'\d{2}[/-]\d{2}[/-]\d{4}', datestr)
['23-10-2018', '23/10/2018', '10/23/2018']
خوب همانطور که در خروجی کد فوق مشاهده میکنید تاریخ های که ابتدا دو رقمی بودن سپس با علامتهای / و - جدا شدند و دوباره دو رقم و علامت / و - تکرار شدند و در نهایت نیز 4 رقم برای سال ذکر شده بعنوان خروجی نمایش داده خواهند شد.
حالا برای اینکه بهبود بدیم این کد رو تا برای حالت دوم هم پوشش بده کافیه بخش آخر یه تغییر ایجاد کنیم بصورت زیر:(در واقع مقدار سال میتونه دو رقم تا 4 رقم رو در نظر بگیره)
» re.findall(r'\d{2}[/-]\d{2}[/-]\d{2,4}', datestr)
['23-10-2018', '23/10/2018', '23/10/18', '10/23/2018']
دقت کنید زمانهای این امکان وجود داره که تاریخ روز و ماه بصورت تک رقمی نوشته بشه کافیه کد رو بصورت زیر اصلاح کنیم:
re.findall(r'\d{1,2}[/-]\d{1,2}[/-]\d{2,4}', datestr)
عبارت های منظم برای تاریخ ها (برای چهار حالت دوم)
برای این حالت میتونیم عبارت منظم رو بصورت زیر بنویسیم شاید در نگاه اول باید خروجی درست به ما بده و حالت زیر رو بعنوان خروجی برگردونه :
23 oct 2018
» re.findall(r'\d{2} (Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec) \d{4}', datestr)
['Oct']
ولی میبینیم جواب ما اشتباه خواهد شد.دلیلش وجود پرانتز است که سبب میشود عبارت داخل پرانتز بعنوان یک متغیر جداگانه در نظر گرفته شوید. برای اینکه کد رو اصلاح کنیم از علامت :? استفاده میکنیم که سبب می شود تا عبارت داخل پرانتر بعنوان یک متغیر جدا در نظر گرفته نشود :
» re.findall(r'\d{2} (?:Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec) \d{4}', datestr)
['23 Oct 2018']
حالا برای بهبودش که حالت زیر رو هم در نظر بگیره از این روش استفاده میکنیم:
23 october 2018
» re.findall(r'\d{2} (?:Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec)[a-z]* \d{4}', datestr)
['23 Oct 2018', '23 October 2018']
متاکارکتر *[a-z] سبب میشه تمام کارکترهای بعد از ماه تکرار میشه رو هم در نظر بگیره و این کارکترها میتونه صفر یا هر تعدادی باشه.
اما باز عبارت منظم رو بهبود بدهیم که دو حالت آخر رو در نظر بگیره، میتونیم از علامت سوال استفاده کنید. علت استفاده از علامت سوال اینه که هر عبارت قبل از اون میتونه یکبار بیاد و میتونه کلا نیاد. بیاییم کدشو رو بنویسیم.
» re.findall(r'(?:\d{2} )?(?:Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec)[a-z]* (?:\d{2}, )?\d{4}', datestr)
['23 Oct 2018', '23 October 2018', 'Oct 23, 2018', 'October 23, 2018']

❇️ متاکارکترها - انطباق کارکترها
1️⃣ . (نقطه) : تنها یک کارکتر (هر نوع کارکتری) میتواند ظاهر گردد.
2️⃣ ^ : این علامت در داخل یک کروشه به معنی این است که کارکترهای بعد از آن نباید ظاهر گردند.
3️⃣ $ : این علامت در پایان یک رشته به این معنی که عبارت مورد جستجو باید با عبارتی که قبل از $ می آید شروع شود.
4️⃣ [ ] : انطباق با مجموعه از کارکترهای درون کروشه
5️⃣ متاکارکتر [a-z] : مطابقت با یکی از رشته های a,b,...,z
6️⃣ متاکارکتر [abc^] : مطابقت با کارکترهای که a,b,c نیستند.
7️⃣ متاکارکتر a|b : مطابقت میکند با کارکتری که a یا b باشد. در جاییکه a و b رشته هستند.
8️⃣ ( ) : محدوده ای برای عملگرها
9️⃣ \ : کارکترهای خاص (t , \n , \b\)
❇️ متاکارکترها - نمادهای کارکتری
1️⃣ متاکارکتر b\ : انطباق مرز کلمات
2️⃣ متاکارکتر d\ : رقم ها ، همه اعداد شامل [0-9]
3️⃣ متاکارکتر D\ : غیر از رقم، هر موردی جز اعداد [9-0^]
4️⃣ متاکارکتر s\ : تمام فضاهای خالی، مانند [t\n\r\f\v\ ]
5️⃣ متاکارکتر S\ : عدم فضاهای خالی، مانند [t\n\r\f\v\ ^]
6️⃣ متاکارکتر w\ : تمام کارکترهای الفبایی و عددی، شامل [ _a-zA-Z0-9]
7️⃣ متاکارکتر W\ : تمام کارکترهای غیر الفبایی و عددی، شامل [ _a-zA-Z0-9 ^]
❇️ متاکارکترها - تکرار
1️⃣ * : تکرار صفر یا بیشتر
2️⃣ + : تکرار یک بار یا بیشتر
3️⃣ ؟ : تکرار صفر یا یک عبارت قبل از علامت سوال
4️⃣ متاکارکتر {n} : دقیقا n بار تکرار که n بزرگتر و مساوی صفر خواهد بود.
5️⃣ متاکارکتر { ,n} : حداقل n بار تکرار
6️⃣ متاکارکتر {n, } : حداکثر n بار تکرار
7️⃣ متاکارکتر {m,n} : حداقل m بار و حداکثر n بار تکرار
🔵 اگر متاکارکتری رو متوجه نشدید نگران نباشید، در بخش های بعدی مثالهای خواهیم زد که کاملا متوجه گردید. و اگر دوست داشتید اطلاعات بیشتری در مورد این متاکارکترها داشته باشید لینک زیر رو میتونید مشاهده کنید:
❇️ مثالهای بخش متاکارکترها
مثال های این بخش رو، در ادامه همان مثال قبلیمان انجام خواهیم داد. و اگر یادتون باشه اومدیم گفتیم از re.search برای مشخص کردن عبارتهای منظم استفاده میکنیم.که عبارت منظم ما بصورت زیر بود.
@[A-Za-z0-9_]+
🔹متاکارکتر w\ و +
>>> [w for w in text13 if re.search('@\w+', w)]
['@UN', '@UN_Women']
همانطور که مشاهده میکنید این متاکارکتر کل حروف الفبایی، اعداد و آندرلاین رو شامل خواهد شد و لازم نیست دیگر مثل قبل بنویسیم.
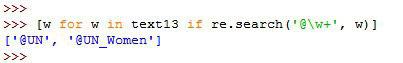
❇️ مثالهای کاربردی
فرض کنید میخواهیم در یک رشته حروف صدادار انگلیسی(a,e,i,o,u) رو پیدا کنیم. بعنوان مثال رشته زیر رو در نظر خواهیم گرفت.
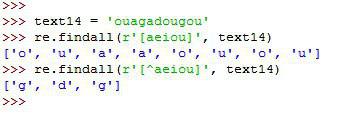
»> text14 = 'ouagadougou'
با استفاده از متد findall و مشخص کرن حروف صدا دار، تمام کارکترهای صدادار را بعنوان خروجی برمیگردانیم.
»> re.findall(r'[aeiou]', text14)
['o', 'u', 'a', 'a', 'o', 'u', 'o', 'u']
اگر بخواهیم حروف غیرصدادار (در واقع حروف بیصدا) را استخراج کنیم کافیه از علامت ^ بدین منظور استفاده کنیم
»> re.findall(r'[^aeiou]', text14)
['g', 'd', 'g']
❇️ پیدا کردن الگوهای با عبارتهای منظم
اینکه بگوییم چیزی با @ شروع میگردد یک الگو می باشد برای ما کافی نیست. بلکه نشانه های است که با @ شروع می شوند و چیزی رو باید دنبال کنند.
برای مثال چگونه میتوانیم تشخیص دهیم که اگر @ در جمله ای ذکر شد آن شامل الگو خاص ما خواهد شد یا خیر. حالتهای که ممکن است بعد از @ وارد شود و آن کلمه را تبدیل به یک الگو خاص نمایید رو یادداشت میکنیم:
انظباق چیزهای بعد از @
- حروف الفبا
-اعداد
-نشانه های خاصی مانند (_)
مثال :
@UN_Spokesperson
@Python
@10years
بنابراین بعد از @ میتواند عبارتهای زیر قرار گیرد:
@[A-Za-z0-9_]+
حروف الفبای بزرگ و کوچک، اعداد صفر تا 9 ، آندرلاین
با علامت + بعد از کروشه مشخص میکنیم این عبارتها میتوانند تکرار گردند.
حالا در ادامه نحوه نوشتن کد برای این عبارت منظم را خواهیم گفت
❇️ حالا بیاییم مثال قبل رو ادامه بدهیم جایی که کلمات با @ شروع میشدند. برای عبارتهای منظم ما یک کتابخانه re داریم که باید ابتدا ایمپورتش کنیم.
در واقع این کتابخانه برای عبارتهای منظم هست و دو حرف اول Regular Expressions هست.
برای این مورد خاص از متد search برای پیدا کردن عبارت منظمی که گفتیم استفاده میکنیم.
>>> import re
>>> [w for w in text13 if re.search('@[A-Za-z0-9_]+', w)]
['@UN', '@UN_Women']
الان در نتیجه مشاهده میکنیم که @ اول که بعدش یک فاصله بود در خروجی چاپ نخواهد کرد. و تمام الگوهای مورد نظر ما فقط در خروجی نمایش داده شد.
یکبار دیگه عبارت منظمی که استفاده کردیم رو تجزیه و تحلیل میکنیم:
@[A-Za-z0-9_]+
این عبارت منظم از سه بخش تشکیل شده است.
1- بخش اول علامت @ است و به قید و شرط باید استفاده گردد.
2- بخش دوم حروف بزرگ A-Z و حروف کوچک a-z و اعداد بین صفر تا نه خواهد بود . دقت کنید همه اعدادهای چند رقمی هم از این 10 عدد صفر تا نه تشکیل شده اند. همچنین آندرلاین (_) هم میتواند قرار داشته باشد. این بخش داخل یک کروشه قرار خواهد گرفت.
3- بخش سوم علامت + است که بعد از کروشه خواهد آمد. این علامت نشان دهنده این است که عبارتهای داخل کروشه میتوانند تکرار گردند.یعنی شما میتوانید یک عدد را بارها تکرار کنید یا حروف الفبای بزرگ و کوچک را تکرار نمایید.که به این علامت متاکارکتر در عبارتهای منظم گویند که در بخش بعد توضیحات بیشتری ارائه خواهیم کرد.