✅ مثالهای گوناگون
🔹 تابع split بصورت پیش فرض رشته ها رو از طریق space یا همون فاصله جدا میکنه و کلمات رو استخراج میکنه، اما ما میتونیم داخل پرانتز کارکتر دلخواه خودمون رو بعنوان میعار جدا کردن در نظر بگیریم. مثال زیر رو ببنید:
>>> text4 = "ouagadougou"
>>> text5 = text4.split('ou')
>>> text5
['', 'agad', 'g', '']
▪️خوب در مثال بالا رشته رو بر اساس کارکتر ou جدا کرد.دقت کنید که ما text4 رو نمیتونیم بر اساس میعار فاصله جدا کنیم چون هیچ فاصله ای در این رشته وجود نداره و اگر داخل پرانتر دستور split خالی باشه به ارور خواهیم خورد.
🔹 در دوره مقدماتی در مورد لیست صحبت کردیم و اگر بخواهیم text4 رو تبدیل به لیست کنیم کارکتر به کارکتر داخل یک لیست برامون قرار میده.
>>> list(text4)
['o', 'u', 'a', 'g', 'a', 'd', 'o', 'u', 'g', 'o', 'u']
🔹با استفاده از حلقه for هم امکان ایجاد لیست فوق وجود داره، مثال رو ببنید.
>>> [c for c in text4]
['o', 'u', 'a', 'g', 'a', 'd', 'o', 'u', 'g', 'o', 'u']
🔹 حالا اگر بخواهیم دوباره ou رو به text5 متصل کنیم از دستور join برای اینکار استفاده میکنیم.و نحوه استفاده بصورت زیر خواهد بود
>>> 'ou'.join(text5)
'ouagadougou'

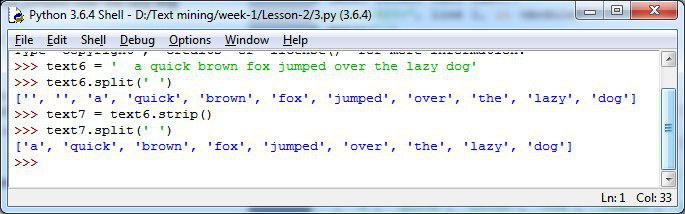
🔹یک رشته جدید تو این مثال خواهیم زد که ابتدای رشته دوتا فاصله وجود داره؛ ما اول میاییم با دستور split کلمات رو جدا میکنیم و اتفاقی که میفته فاصله های ابتدایی رو بعنوان یک کلمه مجزا درنظر میگیره
>>> text6 = ' a quick brown fox jumped over the lazy dog'
>>> text6.split(' ')
['', '', 'a', 'quick', 'brown', 'fox', 'jumped', 'over', 'the', 'lazy', 'dog']
🔹حالا اگر بخواهیم این فاصله های اضافی رو برداریم و با توجه به اینکه این موضوع برای مباحث متن کاوی مهم هست که موارد اضافه رو حذف کنیم از دستور strip برای اینکار استفاده خواهیم کرد.
>>> text7 = text6.strip()
>>> text7.split(' ')
['a', 'quick', 'brown', 'fox', 'jumped', 'over', 'the', 'lazy', 'dog']
▪️همانطور که در بالا مشاهده میکنیم دیگر فاصله ها در لیست ما قرار ندارند.
مثال دستور find و replace
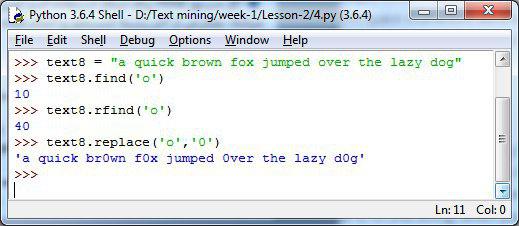
🔹 در متن جدید میخواهیم کارکتر o رو پیدا کنیم اگر از دستور find استفاده کنیم اولین کارکتر o در متن رو پیدا میکنه و اندیسش رو بعنوان خروجی برمیگردونه. (اندیس در پایتون از صفر شروع میشه)
>>> text8 = "a quick brown fox jumped over the lazy dog"
>>> text8.find('o')
10
🔹 اگر دستور rfind برای اینکار استفاده کنید آخرین کارکتر o در رشته رو پیدا میکنه، بعبارتی از آخر رشته جستجو رو انجام میده.
>>> text8.rfind('o')
40
🔹 و برای جایگزینی کارکتر o با مقدار صفر (0) میتونیم از دستور replace بصورت زیر استفاده کنیم
>>> text8.replace('o','0')
'a quick br0wn f0x jumped 0ver the lazy d0g'