❇️ متاکارکترها - انطباق کارکترها
1️⃣ . (نقطه) : تنها یک کارکتر (هر نوع کارکتری) میتواند ظاهر گردد.
2️⃣ ^ : این علامت در داخل یک کروشه به معنی این است که کارکترهای بعد از آن نباید ظاهر گردند.
3️⃣ $ : این علامت در پایان یک رشته به این معنی که عبارت مورد جستجو باید با عبارتی که قبل از $ می آید شروع شود.
4️⃣ [ ] : انطباق با مجموعه از کارکترهای درون کروشه
5️⃣ متاکارکتر [a-z] : مطابقت با یکی از رشته های a,b,...,z
6️⃣ متاکارکتر [abc^] : مطابقت با کارکترهای که a,b,c نیستند.
7️⃣ متاکارکتر a|b : مطابقت میکند با کارکتری که a یا b باشد. در جاییکه a و b رشته هستند.
8️⃣ ( ) : محدوده ای برای عملگرها
9️⃣ \ : کارکترهای خاص (t , \n , \b\)
❇️ متاکارکترها - نمادهای کارکتری
1️⃣ متاکارکتر b\ : انطباق مرز کلمات
2️⃣ متاکارکتر d\ : رقم ها ، همه اعداد شامل [0-9]
3️⃣ متاکارکتر D\ : غیر از رقم، هر موردی جز اعداد [9-0^]
4️⃣ متاکارکتر s\ : تمام فضاهای خالی، مانند [t\n\r\f\v\ ]
5️⃣ متاکارکتر S\ : عدم فضاهای خالی، مانند [t\n\r\f\v\ ^]
6️⃣ متاکارکتر w\ : تمام کارکترهای الفبایی و عددی، شامل [ _a-zA-Z0-9]
7️⃣ متاکارکتر W\ : تمام کارکترهای غیر الفبایی و عددی، شامل [ _a-zA-Z0-9 ^]
❇️ متاکارکترها - تکرار
1️⃣ * : تکرار صفر یا بیشتر
2️⃣ + : تکرار یک بار یا بیشتر
3️⃣ ؟ : تکرار صفر یا یک عبارت قبل از علامت سوال
4️⃣ متاکارکتر {n} : دقیقا n بار تکرار که n بزرگتر و مساوی صفر خواهد بود.
5️⃣ متاکارکتر { ,n} : حداقل n بار تکرار
6️⃣ متاکارکتر {n, } : حداکثر n بار تکرار
7️⃣ متاکارکتر {m,n} : حداقل m بار و حداکثر n بار تکرار
🔵 اگر متاکارکتری رو متوجه نشدید نگران نباشید، در بخش های بعدی مثالهای خواهیم زد که کاملا متوجه گردید. و اگر دوست داشتید اطلاعات بیشتری در مورد این متاکارکترها داشته باشید لینک زیر رو میتونید مشاهده کنید:
❇️ مثالهای بخش متاکارکترها
مثال های این بخش رو، در ادامه همان مثال قبلیمان انجام خواهیم داد. و اگر یادتون باشه اومدیم گفتیم از re.search برای مشخص کردن عبارتهای منظم استفاده میکنیم.که عبارت منظم ما بصورت زیر بود.
@[A-Za-z0-9_]+
🔹متاکارکتر w\ و +
>>> [w for w in text13 if re.search('@\w+', w)]
['@UN', '@UN_Women']
همانطور که مشاهده میکنید این متاکارکتر کل حروف الفبایی، اعداد و آندرلاین رو شامل خواهد شد و لازم نیست دیگر مثل قبل بنویسیم.
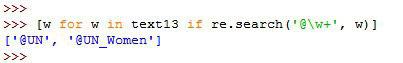
❇️ مثالهای کاربردی
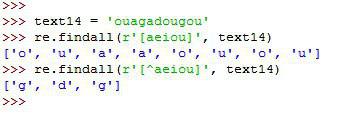
فرض کنید میخواهیم در یک رشته حروف صدادار انگلیسی(a,e,i,o,u) رو پیدا کنیم. بعنوان مثال رشته زیر رو در نظر خواهیم گرفت.
»> text14 = 'ouagadougou'
با استفاده از متد findall و مشخص کرن حروف صدا دار، تمام کارکترهای صدادار را بعنوان خروجی برمیگردانیم.
»> re.findall(r'[aeiou]', text14)
['o', 'u', 'a', 'a', 'o', 'u', 'o', 'u']
اگر بخواهیم حروف غیرصدادار (در واقع حروف بیصدا) را استخراج کنیم کافیه از علامت ^ بدین منظور استفاده کنیم
»> re.findall(r'[^aeiou]', text14)
['g', 'd', 'g']