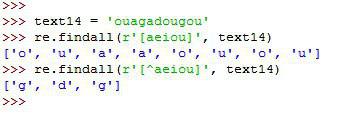
متد بعدی extract می باشد که میخواهیم رشته های رو استخراج کنیم که منطبق بر یک سری گروههای داخل پرانتز باشد. (مجددا تاکید میکنیم عبارت داخل پرانتز را بعنوان یک گروه در نظر میگیریم.)
در رشته ورودی اگر دقت کنیم میبینم زمان ها بصورت ساعت و دقیقه می باشد. تمام دقایق در این مثال ما بصورت دو رقمی بوده اما ساعت ممکن است یک رقمی یا دو رقمی باشد. پس عبارت منظم زیر رو برای پیدا کردن زمان در رشته و مجزا کردن آن در یک ستون دیگر استفاده میکنیم.
df['text'].str.extract(r'(\d?\d):(\d\d)')
0 1
0 2 45
1 11 30
2 7 00
3 11 15
4 08 1
عبارت منظم بالا در داخل یک پرانتز دو رقم رو در نظر خواهد گرفت اما علامت سوالی که در پرانتز اول وجود داره به این دلیل هست که اعلام کنه رقم اول میتونه باشه و میتونه هم نباشه که این مورد برای ساعت کاربرد داره.
نکته ای که وجود داره اینه که در رشته پنجم ما دو تا زمان داشتیم اما فقط اولی رو چاپ کرد. برای این که مشکل رو رفع کنیم از متد extractall استفاده میکنیم و عبارت منظم رو هم طوری تغییر میدهیم که علامت pm یا am بعد ساعت هم در خروجی چاپ گردد.
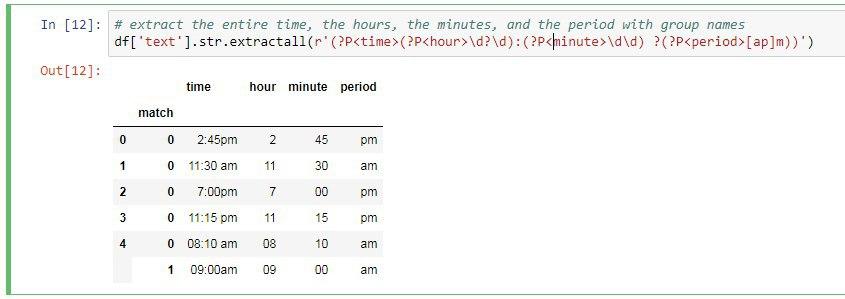
حالا ما چهار تا گروه میخواهیم ایجاد کنیم گروه اول کل عبارت رو چاپ میکنه در واقع زمان رو چاپ میکنه و برای همین باید کل عبارت داخل پرانتز قرار بگیره. گروه دوم ساعت، گروه سوم دقیقه و گروه چهارم هم صبح یا عصر بودن رو چاپ خواهد کرد.
خروجی برنامه در تصویر بعدی قرار دارد.
اما یک نکته وجود علامت سوال قبل از مشخص کردن صبح یا عصر بودن هست.دلیل این مورد بخاطر وجود فاصله بین ساعت و pm یا am هست که در بعضی از رشته ها این فاصله وجود داره و در بعضی ها نبود و ما هم برای همین یک اسپس علامت سوال در نظر گرفتیم تا وجودش الزامی نباشه و اختیاری باشه.

حالا در انتها اگر بخواهیم برای ستون ها ما نامی رو مشخص کنیم کافیه از همان نام گروه برای اینکار استفاده کنیم. برای ایجاد نام گروه از دستور زیر استفاده میکنیم:
و بجای GroupName هر نامی که دوست داشتید میتوانید قرار بدهید.
دقت کنید محل قرار گرفتن نام گروه بعد از پرانتز باز همان گروه می باشد.