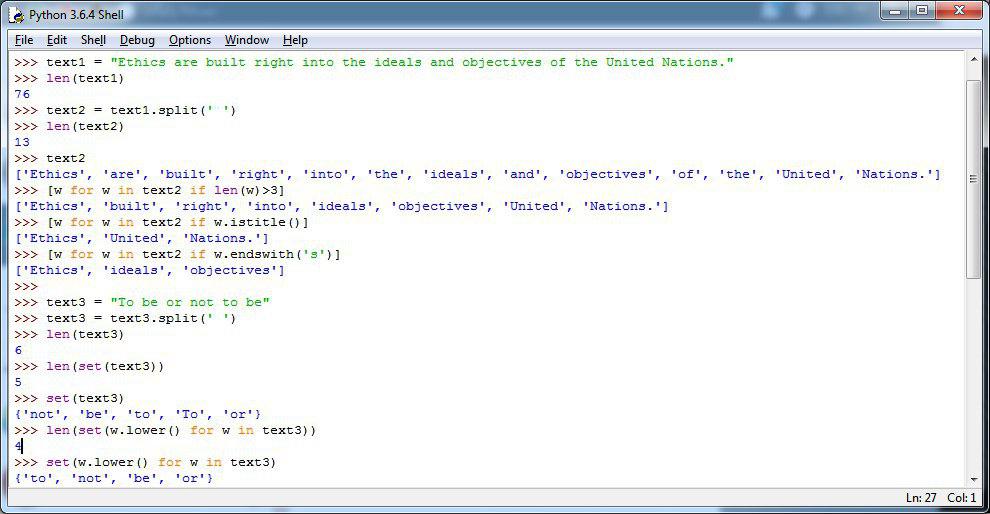
✅ معرفی توابع پایتون برای کلمات
🔹 در این بخش یک تعریف کلی از این توابع خواهیم داشت و در بخش های بعدی مثال های رو بیان خواهیم کرد.
1️⃣ کلماتی که با یک حرف خاص شروع خواهند شد.
s.startswith()
2️⃣ کلماتی که با یک حرف خاص به اتمام می رسند.(در بخش قبل مثال زدیم)
s.endswith()
3️⃣ بررسی وجود یک کلمه در داخل رشته با دستور in
T in s
4️⃣ تشخیص حروف بزرگ و کوچک در کلمات و همچنین یافتن کلماتی که با حرف بزرگ شروع خواهند شد.
s.isupper() ; s.islower() ; s.istitle()
5️⃣تشخیص حروف الفبا یا عدد.
s.isalpha() ; s.isdigit() ; s.isalnum()
▪️تابع اول برای تشخیص حروف الفبا در رشته می باشد که شامل عدد و کارکترهای خاص نباشد.
▪️تابع دوم تشخیص عدد در رشته می باشد.
▪️و تایع سوم میتونه شامل الفبا و عدد باشد اما کارکترهای خاص مثل فاصله و ... را شامل نخواهد شد.
🔸 خروجی سه تا تابع فوق True یا False می باشد.
🔹 در بخش های بعدی برای هر یک از موارد بالا مثال های خواهیم زد.