📗در این درس با کتابخانه pandas برای پردازش داده های متنی آشنا شدیم
📕این کتابخانه روشها و متدهای زیادی را برای پردازش داده های متنی دارد که با استفاد این روش ها و ترکیب ها قادر خواهیم بود برخی از پرازش های متنی بسیار قدرتمند رو با pandas انجام دهیم.
مجله خبری برنامهنویسی پایتون
مرکز آموزش و رقابت برنامه نویسی پایتون

زبان پایتون (Python) در سال ۱۹۹۱ توسط یک برنامهنویس هلندی به نام گیدو ون روسوم (Guido van Rossum) ابداع شد و از آن زمان تا کنون رشد قابل ملاحظهای را شاهد بوده است.
اگر چه وی در آن زمان گفته بود: «من به هیچ وجه قصد ندارم زبانی بسازم که به طور گسترده مورد استفاده قرار بگیرد» ولی اکنون و با گذشت نزدیک به سه دهه از آن تاریخ، پایتون تقریباً تمام رقبای خود را کنار زده و به اندازهای محبوبیت یافته که حتی افراد مبتدی نیز کدنویسی را با آن شروع میکنند.
در یک سال گذشته، «Python» یکی از کلماتی بود که شهروندان آمریکایی بسیار زیاد در گوگل جستجو کردهاند، حتی بیشتر از نام ستارههای تلویزیونی.
طبقه بندی موضوعی
-
برنامه نویسی
(۳۳) -
اخبار
(۲۱) -
جشنواره تخفیف
(۶) -
استخدام
(۴) -
یادگیری ماشین با پایتون
(۳) -
مطالب آموزشی
(۵) -
متن کاوی
(۲۰) -
چالش
(۱) -
کتاب
(۱) -
کتابچه
(۳) -
وبینار
(۱)
کلمات کلیدی
آموزش پایتون
متن کاوی با پایتون
python
متن کاوی
یادگیری ماشین
پایتون
text mining
استخدام برنامه نویس پایتون
یادگیری ماشین با پایتون
پایتون در یادگیری عمیق
Pandas
پایتون برای علم داده
استخدام
محبوب ترین زبان برنامه نویسی
هوش مصنوعی
عبارت منظم در پایتون
replace
استخراج متن در پایتون
کد تخفیف یلدا
یادگیری عمیق
وب سایت آموزشی پایتون
NumPy
Matplotlib
Cheat Sheet
جشنواره تخفیف
پردازش تصویر
ریاضی
jupyter notebook
وبینار
ات ساین
بایگانی
- فروردين ۱۳۹۹ (۲)
- اسفند ۱۳۹۸ (۳)
- بهمن ۱۳۹۸ (۱)
- دی ۱۳۹۸ (۳)
- آذر ۱۳۹۸ (۸)
- شهریور ۱۳۹۸ (۳)
- تیر ۱۳۹۸ (۲)
- خرداد ۱۳۹۸ (۱)
- ارديبهشت ۱۳۹۸ (۳)
- فروردين ۱۳۹۸ (۷)
- اسفند ۱۳۹۷ (۴)
- بهمن ۱۳۹۷ (۱)
- دی ۱۳۹۷ (۱)
- آذر ۱۳۹۷ (۴)
- آبان ۱۳۹۷ (۱۸)
- مهر ۱۳۹۷ (۱۴)
آخرین مطالب
-
۹۹/۰۱/۱۱تخفیف بزرگ چالش پایتون در سال 99
-
۹۸/۱۰/۱۲کتابچه پایتون : کتابخانه scrappy
-
۹۸/۱۰/۱۰کتابچه پایتون : کتابخانه PIL
پیوندها

متد بعدی extract می باشد که میخواهیم رشته های رو استخراج کنیم که منطبق بر یک سری گروههای داخل پرانتز باشد. (مجددا تاکید میکنیم عبارت داخل پرانتز را بعنوان یک گروه در نظر میگیریم.)
در رشته ورودی اگر دقت کنیم میبینم زمان ها بصورت ساعت و دقیقه می باشد. تمام دقایق در این مثال ما بصورت دو رقمی بوده اما ساعت ممکن است یک رقمی یا دو رقمی باشد. پس عبارت منظم زیر رو برای پیدا کردن زمان در رشته و مجزا کردن آن در یک ستون دیگر استفاده میکنیم.
df['text'].str.extract(r'(\d?\d):(\d\d)')
0 1
0 2 45
1 11 30
2 7 00
3 11 15
4 08 1
عبارت منظم بالا در داخل یک پرانتز دو رقم رو در نظر خواهد گرفت اما علامت سوالی که در پرانتز اول وجود داره به این دلیل هست که اعلام کنه رقم اول میتونه باشه و میتونه هم نباشه که این مورد برای ساعت کاربرد داره.
نکته ای که وجود داره اینه که در رشته پنجم ما دو تا زمان داشتیم اما فقط اولی رو چاپ کرد. برای این که مشکل رو رفع کنیم از متد extractall استفاده میکنیم و عبارت منظم رو هم طوری تغییر میدهیم که علامت pm یا am بعد ساعت هم در خروجی چاپ گردد.
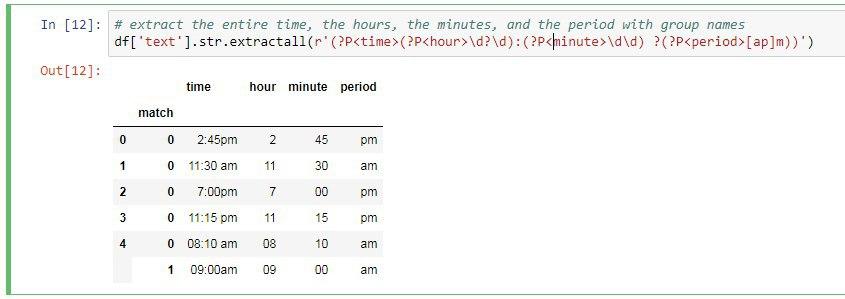
حالا ما چهار تا گروه میخواهیم ایجاد کنیم گروه اول کل عبارت رو چاپ میکنه در واقع زمان رو چاپ میکنه و برای همین باید کل عبارت داخل پرانتز قرار بگیره. گروه دوم ساعت، گروه سوم دقیقه و گروه چهارم هم صبح یا عصر بودن رو چاپ خواهد کرد.
df['text'].str.extractall(r'((\d?\d):(\d\d) ?([ap]m))
خروجی برنامه در تصویر بعدی قرار دارد.
اما یک نکته وجود علامت سوال قبل از مشخص کردن صبح یا عصر بودن هست.دلیل این مورد بخاطر وجود فاصله بین ساعت و pm یا am هست که در بعضی از رشته ها این فاصله وجود داره و در بعضی ها نبود و ما هم برای همین یک اسپس علامت سوال در نظر گرفتیم تا وجودش الزامی نباشه و اختیاری باشه.

حالا در انتها اگر بخواهیم برای ستون ها ما نامی رو مشخص کنیم کافیه از همان نام گروه برای اینکار استفاده کنیم. برای ایجاد نام گروه از دستور زیر استفاده میکنیم:
?P<GroupName>
و بجای GroupName هر نامی که دوست داشتید میتوانید قرار بدهید.
دقت کنید محل قرار گرفتن نام گروه بعد از پرانتز باز همان گروه می باشد.
df['text'].str.extractall(r'(?P<time>(?P<hour>\d?\d):(?P<minute>\d\d)?(?P<period>[ap]m))')
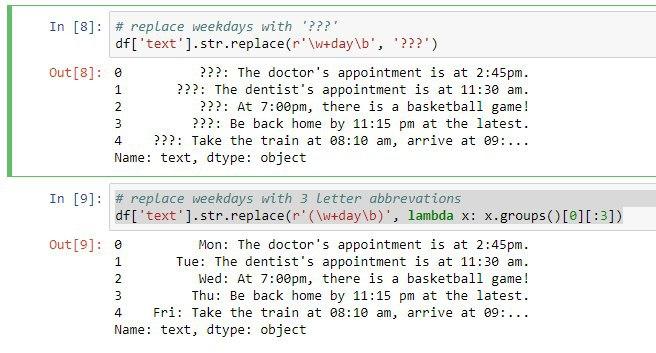
در مثال بعدی میخواهیم از دستوری برای جایگزینی استفاده کنیم بعنوان مثال هر جا روزی در هفته وجود داشت بجای آن روز، سه تا علامت سوال قرار بدهیم.
نکته ای که اینجا وجود داره اینه که تمام روزهای هفته ما به کلمه day ختم خواهد شد. در درس قبل گفتیم w برای تمام کارکتر ها استفاده میشه و b هم برای مشخص کردن مرز کلمه یا بعبارت بهتر پیدا کردن یک تطابق در ابتدا یا انتهای کلمه استفاده خواهد شد.
پس میتوانیم از عبارت نامنظم زیر و متد str.replace برای هدفمون استفاده کنیم:
df['text'].str.replace(r'\w+day\b', '???')
0 ???: The doctor's appointment is at 2:45pm.
1 ???: The dentist's appointment is at 11:30 am.
2 ???: At 7:00pm, there is a basketball game!
3 ???: Be back home by 11:15 pm at the latest.
4 ???: Take the train at 08:10 am, arrive at 09:..
حالا اگر فرض بر این باشه بخواهیم تغییر در رشته ایجاد کنیم که بر مبنای کلمه مورد نظر باشه از متدهای replace و lambda استفاده خواهیم کرد. دقت کنید ما متد لامبدا رو در دوره مقدماتی توضیح داده بودیم.
حالا در این مثال میخواهیم بجای روزهای هفته، فقط سه حرف ابتداییش در خروجی قرار بگیره. مثلا بجای Monday عبارت Mon چاپ گردد.
df['text'].str.replace(r'(\w+day\b)', lambda x: x.groups()[0][:3])
0 Mon: The doctor's appointment is at 2:45pm.
1 Tue: The dentist's appointment is at 11:30 am.
2 Wed: At 7:00pm, there is a basketball game!
3 Thu: Be back home by 11:15 pm at the latest.
4 Fri: Take the train at 08:10 am, arrive at 09:..
در کد فوق تابعی که با استفاده از لامبدا مشخص شده برای جدا کردن سه حرف اول روزها هفته است.
در واقع الگوی ما توسط عبارت منظم پیدا میشه و وقتی که داخل پرانتز قرار میدهیم اون رو تبدیل به یک گروه خواهیم کرد سپس توسط replace با سه حرف اول روزهای هفته جایگزین میکنیم.