
رگرسیون – ویژگی ها و برچسب ها
مترجم : آزاده رضازاده همدانی
ویدئوهای آموزش یادگیری ماشین یا پایتون [کلیک کنید]
در دنباله آموزشهای یادگیری ماشین, مثال رگرسیون بر روی دادههای ارزش سهام را ادامه میدهیم: کدهایی که در مرحله قبل نوشتیم به صورت زیر است:
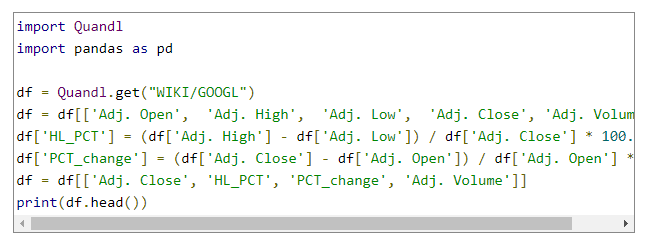
در ادامه باید تعدادی از کتابخانهها را import کنیم:

· numpy: داده ها را به آرایه ( numpy Array ) تبدیل کرده تا بتوان آنها را در اختیار scikit-learn قرار داد.
· ماژول پیش پردازش Preprocessing و اعتبارسنجی CrossValidation: که بیشتر در طول کدنویسی در مورد آنها توضیح خواهیم داد. اما به طور خلاصه کافی است بدانید که پیش پردازش, مرحله پاکسازی و مقیاس بندی دادهها قبل از شروع عملیات یادگیری ماشین و اعتبار سنجی فاز آزمایش نتایج حاصل از اجرای الگوریتم یادگیری ماشین است.
· الگوریتم linear Regression : همان الگوریتم رگرسیون خطی است.
· Svm: الگوریتم یادگیری ماشین به کار رفته برای نمایش نتایج
تا این مرحله دادههای سودمند را دریافت کردهایم اما واقعا یادگیری ماشین چگونه کار میکند؟ در یادگیری بانظارت, مجموعهای از ویژگیها Features و برچسبها Labels را داریم. ویژگیها, خصوصیات توصیفی هر نمونه و برچسب, کلاسی است که در واقع نمونه به آن تعلق دارد و قرار است توسط یادگیری ماشین, پیشبینی شود. یکی از مثالهای رایج در رگرسیون, پیش بینی ارزش حق بیمه اشخاص است. شرکت بیمه اطلاعاتی از جمله سن, سوابق تخلفات رانندگی, سوابق سوء پیشینه و میزان اعتبار بانکی شخص را جمع آوری میکند. البته این دادهها را از طریق اطلاعات مشتریان گذشته دریافت کرده تا حق بیمه مطلوب را پیش بینی نماید. در این مثال مشخصات هر مشتری به عنوان ویژگیها و حق بیمه به عنوان برچسب مرتبط با هر مشتری در نطر گرفته میشود.
در مورد مثال بالا ویژگیها و برچسب چگونه تعیین میشود؟ از آنجایی که هدف پیش بینی قیمت است آیا قیمت به عنوان برچسب در نطر گرفته میشود؟ ویژگیها چطور؟ ویژگیها عبارتند از : قیمت فعلی, درصد high-low و درصد نوسانات تغییرات. قیمت آینده Future price به عنوان برچسب در این مثال در نظر گرفته میشود.
حال کمی جلوتر برویم و خطوطی جدید را اضافه نماییم:

در اینجا ابتدا ستونی را به عنوان ستون پیش بینی(forecast_col) تعیین میکنیم. سپس کلیه مقادیر نامعتبر NAN(not a number) را با مقدار99999- جایگزین مینماییم. از آنجایی که نمیتوان یک داده ناقص با مقادیر نامعتبر را به دستهبند یادگیری ماشین ارسال کرد لذا راهکارهای متعددی برای حذف دادههای ناقص وجود دارد. از جمله: جایگزینی مقادیر نامعتبر با مقدار 99999- که داده را به منزله یک داده پرت تلقی میکند. و همچنین حذف کلیه دادههای ناقص. اما این کار احتمال از دست دادن حجم عطیمی از اطلاعات مفید را ایجاد میکند.
بر خلاف مجموعه داده مربوط به ارزش و تعداد سهام که شامل دادههای کامل و بدون نقصی میباشد, مجموعه دادههای دنیای واقعی بسیار ناقص و نامعتبر و یا به اصطلاح کثیف Messy میباشند. اما شما لزوما نیازی به تضمین صحت همه دادهها نخواهید داشت و حتی میتوانید شرط ببندید که دادههای واقعی مورد استفاده در الگوریتم یادگیری ماشین حتما دارای نقصهایی میباشند. بنابراین باید مراحل آموزش و آزمایش نتایج را به ظور زنده بر روی دادههای واقعی یکسان با تمام ویژگیهای آنها انجام داد.
در نهایت تعداد مواردی که میخواهیم پیشبینی کنیم تعیین میشود (forecast_out) .در بسیاری موارد به طور مثال پیش بینی حق بیمه, "در همان لحظه", تنها به یک عدد نیاز داریم درحالی که اصولا بدنبال پیشبینی تعداد مشخصی از دادهها هستیم. معمولا هدف, پیش بینی %1 تعداد کل رکوردهای موجود در دیتاست در آینده است. این بدین معنی است که مثلا با داشتن 100 روز ارزش سهام ,هدف, پیش بینی ارزش سهام در یک روز آینده است. پس آنچه ا که میخواهید, مشخص کنید! اگر تمایل به پیش بینی قیمت فردا را دارید مقدار forecast-out=1 خواهد بود. و اگر مقدار forecast-out=10 باشد یعنی شما قابلیت پیش بینی قیمتها تا ده روزآینده (یک هفته و نیم آینده) را خواهید داشت.
در مثال اولیه مجموعه ای از مقادیر فعلی را به عنوان ویژگی و قیمت آینده (منظور از آینده %1 تعداد دادههای موجود در دیتاست میباشد )را به عنوان برچسب در نظر گرفتیم. از آنجایی که همه ستونهای فعلی را به عنوان ویژگی در نظر گرفته ایم لذا با یک عملیات ساده موجود در کتابخانه pandas , ستونی جدید برای برچسب ایجاد می نماییم.
تا اینجا ویژگیها و برچسب همه نمونه ها معین گردید. در مرحله بعد پس از انجام عملیات پیش پردازش , نمونه ها در اختیار الگوریتم رگرسیون قرار خواهند گرفت که در بخش های آینده پیرامون آن صحبت خواهد شد.
