عبارت های منظم برای تاریخ ها
تاریخ ها معمولا به شکل متنوعی نوشته خواهند شد. بعنوان مثال اگر بخواهیم بنویسیم 23 اکتبر 2018 میتوانیم به هر یک از صورتهای پایین بنویسیم:
23-10-2018
23/10/2018
23/10/18
10/23/2018
23 oct 2018
23 october 2018
oct 23, 2018
october 23, 2018
عبارت منظمی که میتوانیم برای تاریخ بنویسیم تا مورد اول، دوم و چهارم رو پوشش بده میتونه به این صورت باشه:
\d{2}[/-]\d{2}[/-]\d{4}
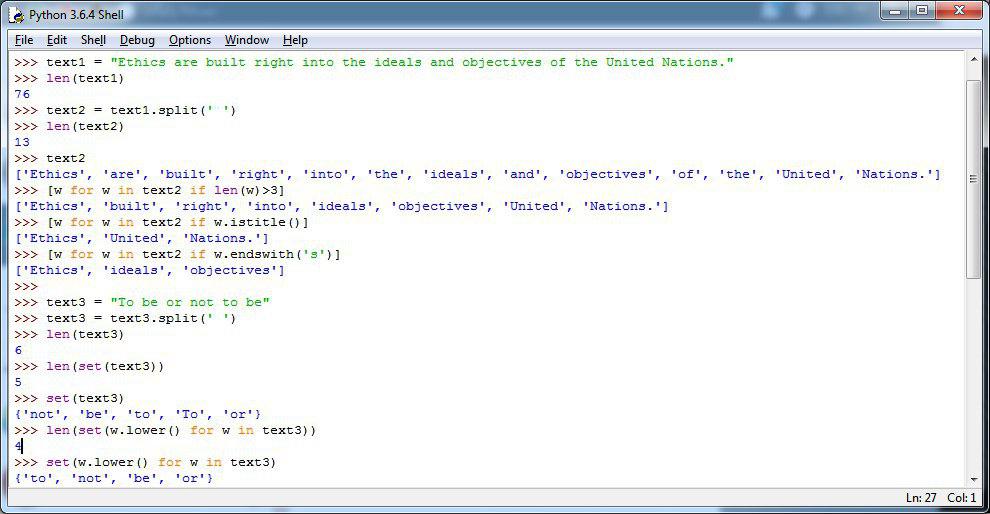
بعنوان مثال رشته زیر رو در نظر بگیرید: (n/ اشاره به خط بعد دارد.)
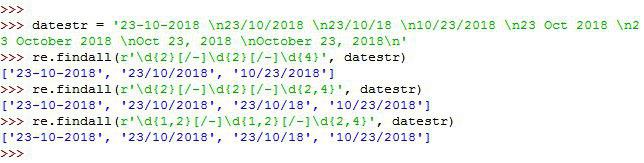
» datestr = '23-10-2018 \n23/10/2018 \n23/10/18 \n10/23/2018 \n23 oct 2018 \n23 october 2018 \noct 23, 2018 \noctober 23, 2018\n'
» re.findall(r'\d{2}[/-]\d{2}[/-]\d{4}', datestr)
['23-10-2018', '23/10/2018', '10/23/2018']
خوب همانطور که در خروجی کد فوق مشاهده میکنید تاریخ های که ابتدا دو رقمی بودن سپس با علامتهای / و - جدا شدند و دوباره دو رقم و علامت / و - تکرار شدند و در نهایت نیز 4 رقم برای سال ذکر شده بعنوان خروجی نمایش داده خواهند شد.
حالا برای اینکه بهبود بدیم این کد رو تا برای حالت دوم هم پوشش بده کافیه بخش آخر یه تغییر ایجاد کنیم بصورت زیر:(در واقع مقدار سال میتونه دو رقم تا 4 رقم رو در نظر بگیره)
» re.findall(r'\d{2}[/-]\d{2}[/-]\d{2,4}', datestr)
['23-10-2018', '23/10/2018', '23/10/18', '10/23/2018']
دقت کنید زمانهای این امکان وجود داره که تاریخ روز و ماه بصورت تک رقمی نوشته بشه کافیه کد رو بصورت زیر اصلاح کنیم:
re.findall(r'\d{1,2}[/-]\d{1,2}[/-]\d{2,4}', datestr)