دراین درس میخواهیم نگاهی به داده های متنی و کار با کتابخانه pandas بپردازیم.
ابتدا بصورت زیر یک داده متنی معرفی خواهیم کرد .و قبل از معرفی داده، کتابخانه pandas رو ایمپورت میکنیم:
import pandas as pd
time_sentences = ["Monday: The doctor's appointment is at 2:45pm.",
"Tuesday: The dentist's appointment is at 11:30 am.",
"Wednesday: At 7:00pm, there is a basketball game!",
"Thursday: Be back home by 11:15 pm at the latest.",
"Friday: Take the train at 08:10 am, arrive at 09:00am."]
برای اینکه برای ستون این داده متنی، اسمی رو قرار بدهیم از تابع DataFrame بصورت زیر استفاده میکنیم
df = pd.DataFrame(time_sentences, columns=['text'])
df
در حال حاضر داده ما شامل یک ستون هست که هر سطر آن یک متن می باشد و هر ورودی ما شامل یک روز در هفته و همچنین یک یا دو ساعت و دقیقه در بین متن می باشد

❇️ با استفاده از ویژگی str میتوانیم به مجموعه ای از روش های پردازش رشته دسترسی پیدا کنیم.
برای مثال متد str.len نشان دهنده طول متن یا همان تعداد کارکترهای هر رشته می باشد.
df['text'].str.len()
دستور بالا برای ستون text از رشته ورودی ، طول هر رشته را محاسبه میکند و در خروجی چاپ میکند. دقت کنید این ستون شامل 5 سطر می باشد و برای هر سطر بصورت جداگانه تعداد کارکترها را نمایش خواهد داد.
0 46
1 50
2 49
3 49
4 54
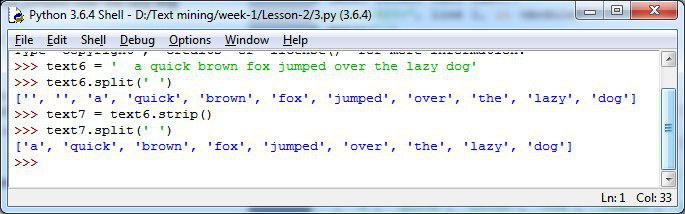
❇️ حالا اگر بخواهیم بجای تعداد کارکتر، تعداد کلمات رو مشخص کنیم. کافیه ابتدا با متد str.split کلمات یک متن رو با استفاده فاصله بین کلمات جدا کنیم سپس برای محاسبه طول اقدام کنیم:
df['text'].str.split().str.len()
0 7
1 8
2 8
3 10
4 10
پس برای مثال رشته اول شامل 7 کلمه و 46 کارکتر می باشد.