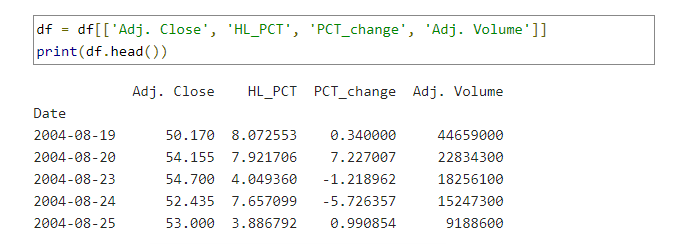
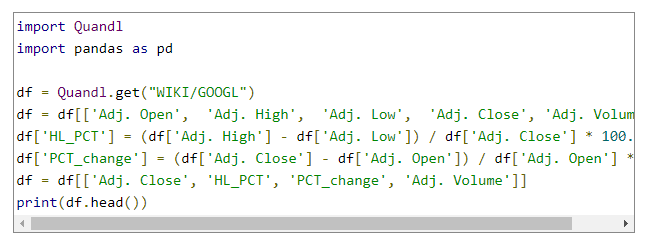
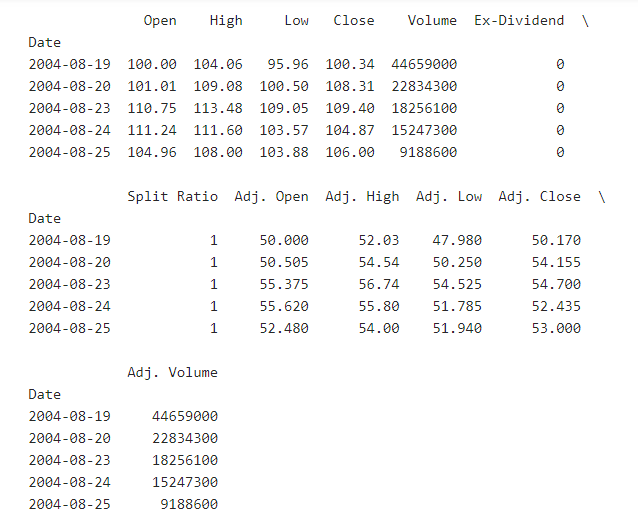
مترجم : آزاده رضازاده همدانی
ویدئوهای آموزش یادگیری ماشین یا پایتون [کلیک کنید]
پیشنیاز
: Scikit-learnو Pandas,
matplotlib
(اگر نسخه علمی از پیش کامپایل شده پایتون
مثل ACtivePython را ذز اختیار دارید پس نیازی به نصب کتابخانههای numpy,Scipy,Scikit-learn,Matplotlib,pandas نیست در غیر این صورت آنها را به صورت
جداگانه نصب نمایید)
همچنین
علاوه بر نصب کتابخانههای فوق , کتابخانه quandl را نیز نصب نمایید. (به qو یا Q هنگام import کتابخانه quandl توجه نمایید!!)
منظور
از رگرسیون در یادگیری ماشین چیست؟ هدف در رگرسیون : دریافت دادههای پیوسته,
پیداکردن متناسب ترین معادله برای دادهها , و سپس پیش بینی مقدار جدید برحسب
معادله بدست آمده. به طور مثال در رگرسیون خطی تنها باید بهترین معادله خط را
مطابق شکل زیر پیدا نمود:
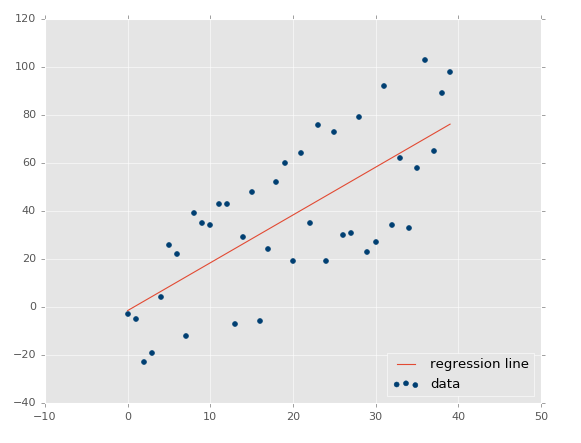
با
داشتن معادله خط میتوان دادههای جدیدی که درآینده دریافت میشوند را تخمین و پیش
بینی نمود. به طور مثال فرض کنید در شکل بالا محور افقی نشاندهنده زمان (تاریخ) و
محور Y عمودی نشان دهنده قیمت باشد. بنابراین با داشتن معادله خط میتوان
قیمتها را در اینده پیش بینی نمود.
یکی از
کاربردهای مرسوم رگرسیون پیش بینی ارزش سهام است بدین صورت که بادرنظر گرفتن روندو
جریان قیمت در طول زمان , و با داشتن مجموعه دادههای پیوسته, ارزش روند جدید سهام
در آینده پیش بینی میشود.
رگرسیون
نوعی یادگیری ماشین با ناظر است. در این حالت فرد خبره(محقق) بارها و بارها نمونهها
و ویژگیها را در اختیار ماشین قرار داده سپس برچسب کلاس دسته بندی صحیح هریک, را
نیز در اختیار آن قرار میدهد تا بدین ترتیب ماشین پروسه دستهبندی را فرابگیرد.
پس از آن که ماشین آموزش داده شد, نوبت به مرحله آزمایش (تست) ماشین میرسد. بدین صورت
که نمونههای دیده نشده ای که برچسب کلاس آن برای فرد خبره معلوم اما برای ماشین
نامعلوم و نامشخص است در اختیار ماشین قرار داه میشود.پاسخهای حاصل از تشخیص
ماشین با پاسخهای اصلی درست مقایسه شده و میزان صحت ماشین اندازهگیری میشود.اگر
صحت به اندازه کافی بالا باشد محقق میتواند این الگوریتم را بر روی دادههای واقعی
اعمال نماید.
از
آنجایی که مثال پرکاربرد رگرسیون, پیش بینی ارزش سهام است پس میتوان با مثال زیر
شروع کرد:
در
ابتدا به داده احتیاج داریم. گاهی اوقات بدست آوردن این دادهها کار آسانی است اما گاهی باید
اطلاعات مدنظر خود را از بین دادههای موجود بیرون کشید مشابه کاری که در این مثال
انجام شده است:
در اینجا از اطلاعات ساده موجود پیرامون ارزش و تعداد سهام در کتابخانه Quandle
استفاده خواهیم کرد که قبلا توسط google
جمع آوری شده است.

در متن
بالا Q در کلمهQuandle باید
با حروف کوچک نوشته شود.
در حال
حاضر این اطلاعات در اختیار ماست: همانطور که مشاهده میکنید حجم آنها برای شروع
کمی زیاد است.
همانطور
که قبلا در مقدمه هم توضیح داده شد, در یادگیری ماشین بخشی وجود دارد که هدف آن
کاهش میزان دادههای ورودی است. در این مثال خاص چند ستون داریم که بسیاری ازآنها
زاید و تکراری بوده و تنها یک زوج از آنها ثابت بوده و تغییر نمیکند. احتمالا همه
با این موضوع موافقیم که داشتن همزمان داده های Regular و دادههای Adjusted امر مطلوبی
نیست. ستونهای Adjasted مطلوبترین اطلاعات را در اختیار ما قرار میدهند
در حالی که ستونهای regular حاوی اطلاعات روزانه بوده که شاید خیلی مفید
نباشند. مثلا سهام دارای بخشی به نام stock
splits(تقسیم سهام)
میباشد که ممکن است یک سهم به 2 سهم تقسیم شود و ارزش سهام نصف شده در حالی که
ارزش آن شرکت نصف نشود. ستونهای adjusted به مرور و در گذر زمان برای stock splits تنظیم میشوند
از اینرو به منظور تحلیل دادهها بسیار قابل اعتمادتر هستند. حالا بهتر است کمی
پیش برویم و نمونه کوچکی از داده ها را دقیق تر بررسی کنیم:
دراینجا
فقط ستونهای adjusted و همچنین ستون volume (تعداد
سهام )راداریم. لازم است پیرامون نکاتی مهم بحث شود:
·
آیا این که افراد تصور میکنند که یادگیری ماشین قادر به خلق
اطلاعات از هیچ است صحیح میباشد؟ خیر در واقع باید اطلاعاتی حتما موجود باشد تا
یادگیری ماشین بتواند آن را برجسته و مشخص نماید.
·
شما به داده های با معنی احتیاج دارید. حال چگونه متوجه
خواهید شد که این دادهها با معنی هستند یا خیر؟ بهترین پاسخ برای این سوال این
است که از فکر و مغز خود استفاده کنید و در مورد آن فکر کنید.
·
آیا قیمتهای گدشته نشاندهنده قیمتهای آینده هستند؟ بعضی
از افراد اینگونه فکر میکنند اما در گذر زمان ثابت شده است که این تصور اشتباه است.
·
الگوهای گذشته چطور؟ آیا در پیشبینی آینده موثر هستند؟
این نظریه تا حدودی میتواند خوب باشد اما در کل هنوز ضعیف است.
·
در راستای بررسی الگوهای گدشته, آیا بررسی روابط بین
تغییرات ارزش سهام و تعداد سهام (volume) در طول زمان به پیشبینی ارزش سهام در
آینده کمک خواهد کرد؟بله این دیدگاه تا حدودی نسبت به نظرات قبلی بهتر شده است.
پس
همانطور که میبینید داشتن داده بیشتر به منزله بهتر بودن داده نیست و هدف در
یادگیری ماشین کسب مفیدترین دادهها میباشد. بدین منظور گاهی نیازاست تاتغییراتی
بر روی اطلاعات خام اولیه صورت پذیرد.
میزان
نوسانات روزانه مثلا کمترین تغییرات رادر نطر بگیرید. به نظر شما بهتر است داده ها
به سادگی مطرح شده (Open, High, Low, Close)و یا به صورت نوسانات و درصد تغییرات( Close, Spread/Volatility,
%change )؟ تصور من این
است درصد تغییرات اطلاعات مفیدتری را به ما میدهد.
بنابراین
همانگونه که تاکنون مشاهده کردید همه دادههای موجود اطلاعات مفیذی را در اختیار
شما قرار نمیدهند, بلکه باید قبل از در اختیار گذاشتن داده ها به صورت ورودی
الگوریتم یادگیری ماشین, تغییراتی را بر روی آنها انجام دهید.
در این
بخش مقدار (high-low)/low*100 محاسبه میشودکه نشاندهنده درصد انتشار بر
اساس ارزش close بوده
و میزان نوسانات را اندازهگیری میکند:

در
انتها درصد تغییرات روزانه محاسبه میشود:

و چهار
ستون زیر نمایش داده میشود: